0. 参考资料
1. 网络结构
ViT 网络是谷歌在 2020 年提出的基于纯 Transformer 实现的分类网络,它完全抛弃了 CNN 网络。 ViT 网络中的 Transformer 与传统意义上的 Transformer 存在明显的不同,传统的 Transformer 是用于 NLP 中的机器翻译任务中,它的结构由 Encoder 和 Decoder 两部分组成,因为要将输入的序列通过 Encoder 网络进行编码,然后将编码后的序列通过 Decoder 解码,最终得到目标语言。但是在视觉任务中,我们只需要对图像进行特征提取,然后将特征通过全链接层输出目标类别。
我们知道,在 NLP 模型中 Transformer 的输入是一个序列,那么对于图像数据, ViT 是将一张图像分成一个个小的 patch ,然后对这些 patch 进行编码。
ViT 网络的特征提取是使用了一个叫做 class token 的结构,该结构是可学习的。它与图像编码后的张量在 dim=1 处进行 cat 操作得到一个新的张量,新张量的第一个元素就是 class token ,这个新的张量与位置编码进行相加后输入到 ViT 网络中,最后学习到的 class token 即为图像的特征图,将这个特征通过全链接层得到类别的输出。
ViT 网络的整体结构如下图所示。
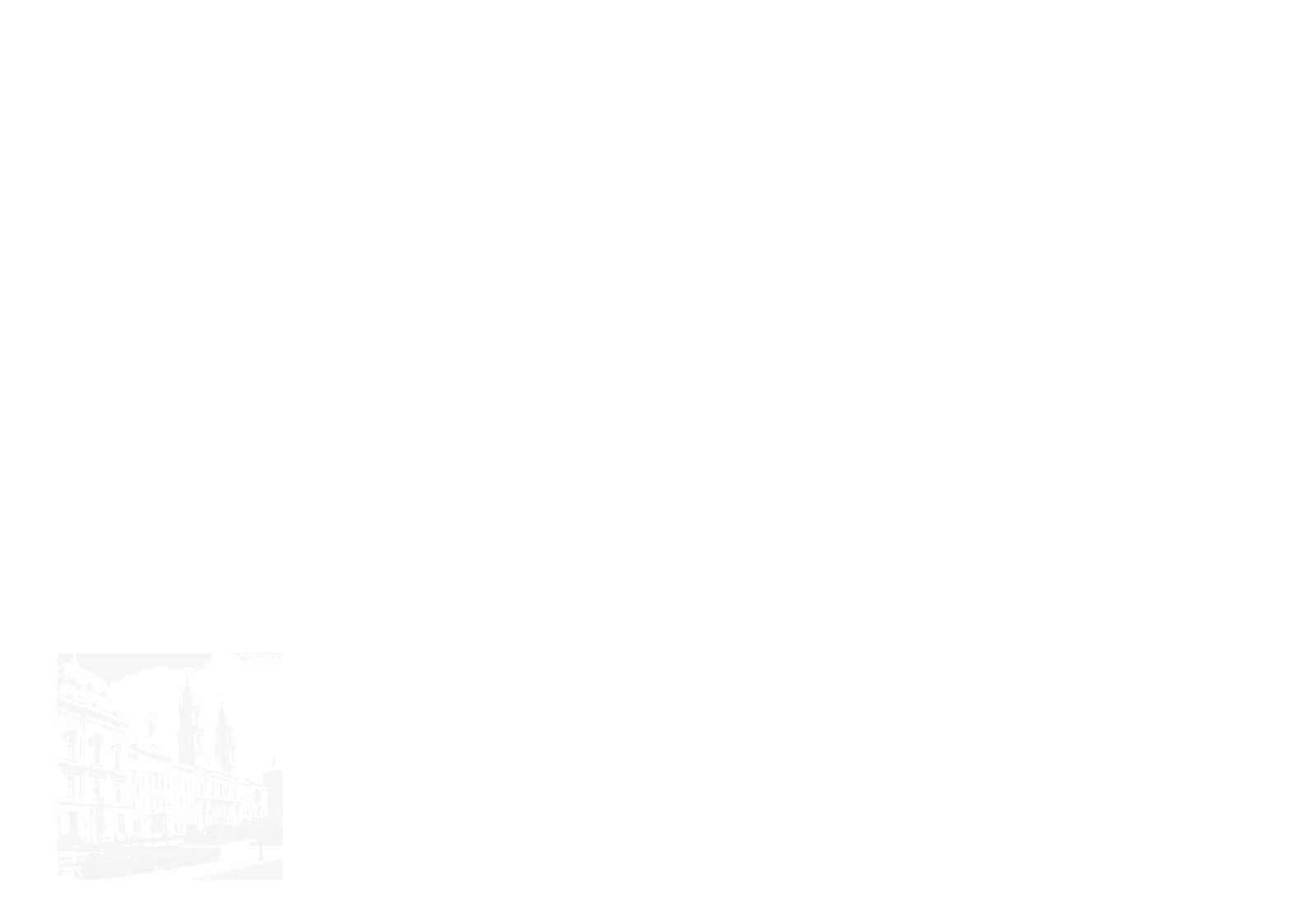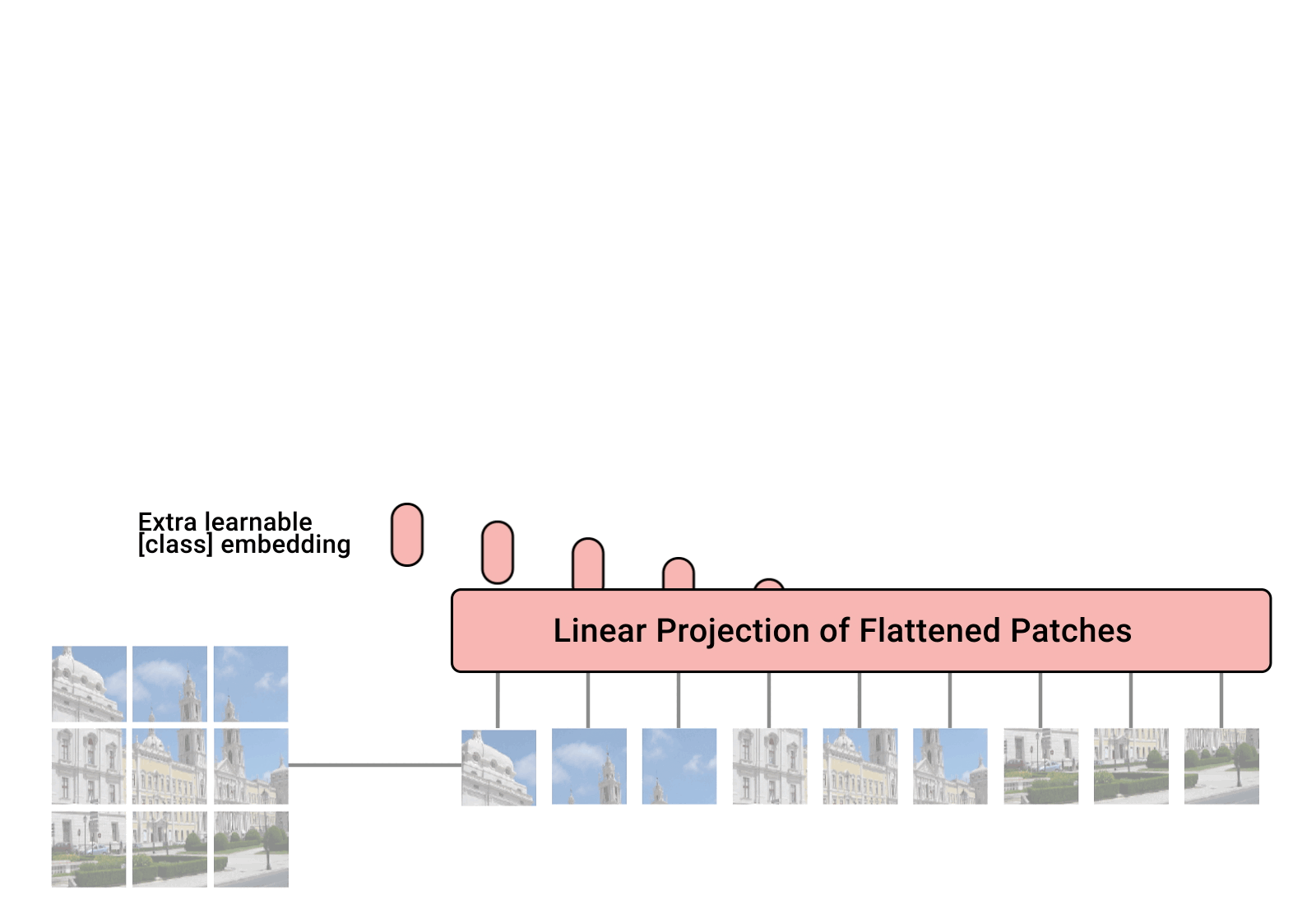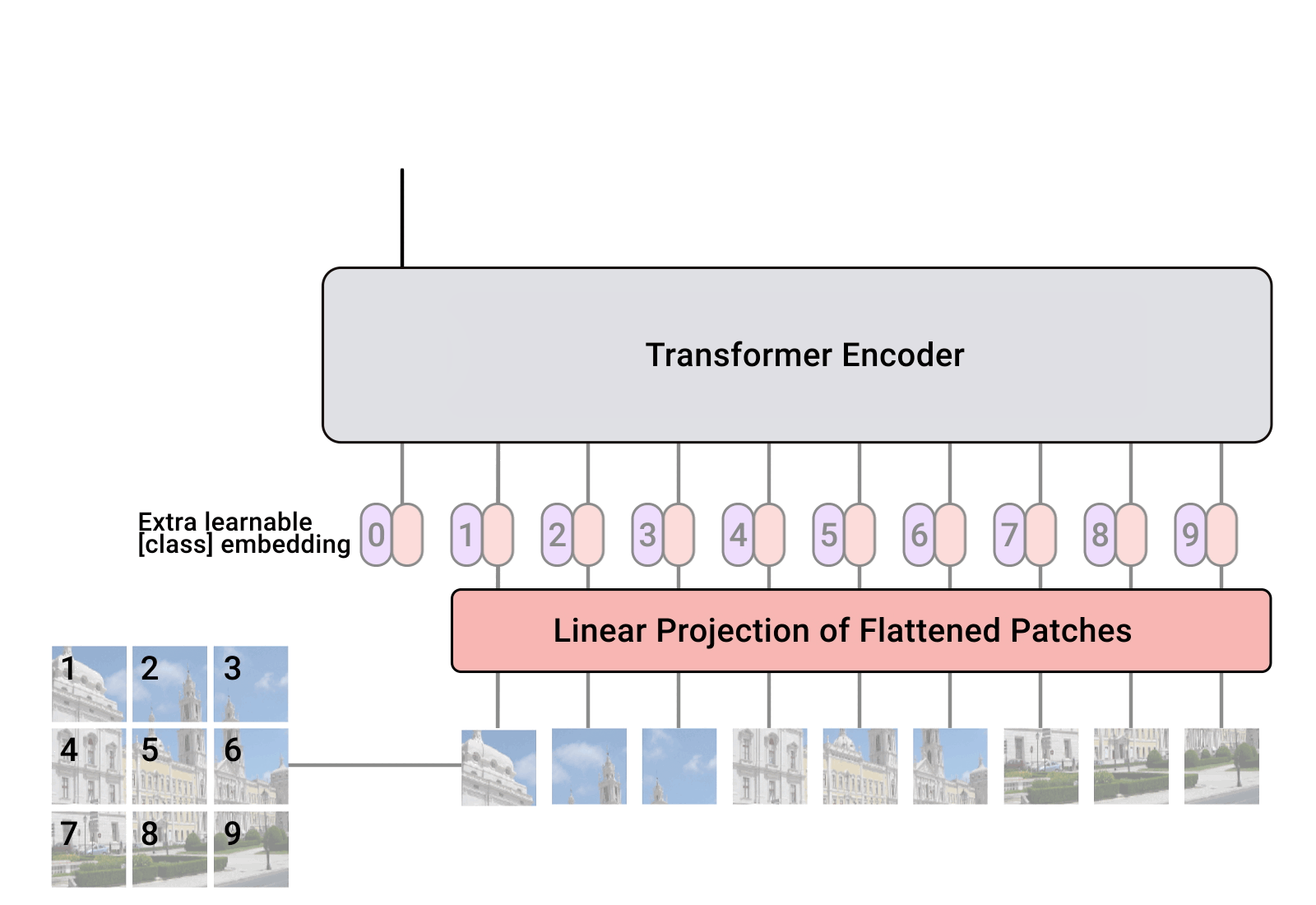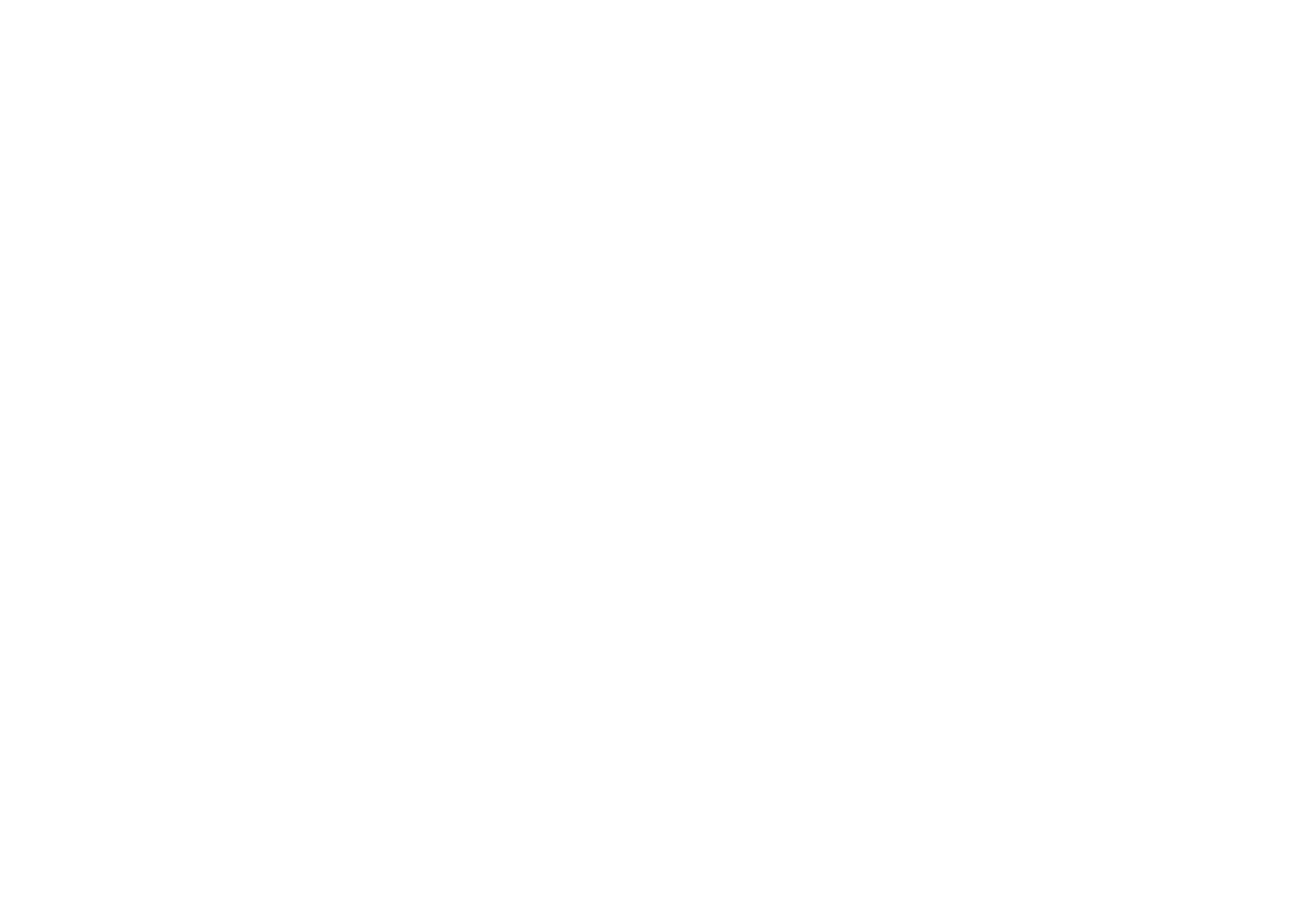
2. 代码解析
ViT 代码整体结构也比较简单,主要是注意张量在网络中传播的过程中维度的变化。下面我们从创建 ViT 网络开始。
ViT 的代码实现中,没有使用像 view 、 reshape 等的函数进行维度的变换,而是使用 einops 库,其实也很简单,看下面代码注释就很好明白了。
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
- 首先要查创建一个 ViT 类
- dim: patch embedding 的维度
- depth: Transformer 结构中 Encoder 的个数
- heads: MSA 的 head 个数
- mlp_dim: Transformer 结构中 FFN 的输出维度
- img: 随机初始化一个维度为 [4, 3, 256, 256] , 4 表示 batch size
- mask: 可选的 mask ,用于委托哪个 patch 去使用 attend
- preds: 调用 ViT 的前向传播函数,输出预测的类别,维度为 [4, 1000]
if __name__ == "__main__": v = ViT( image_size = 256, patch_size = 32, num_classes = 1000, dim = 1024, depth = 6, heads = 16, mlp_dim = 2048, dropout = 0.1, emb_dropout = 0.1 ) img = torch.randn(4, 3, 256, 256) mask = torch.ones(1, 8, 8).bool() # optional mask, designating which patch to attend to # [batch, 1000] preds = v(img, mask = mask)
下面看一下 ViT 类的实现,注释中标注了张量维度的变化。
- 图像的大小是 [256, 256] ,每个 patch 的大小是 [32, 32] ,所以图像被分割成了 64 个 patch
class ViT(nn.Module): def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.): super().__init__() assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.' num_patches = (image_size // patch_size) ** 2 patch_dim = channels * patch_size ** 2 assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)' # img:[4,3,256,256] # patch_size=32 ,每个 patch 的大小是 (32, 32) # h=8 # w=8 # Rearrange: [4, 64, (32*32*3)]=[4, 64, 3072] # patch_dim: 3072 # dim: 1024 # 经过全链接层后,维度由 [4, 64, 3072] -> [4, 64, 1024] self.to_patch_embedding = nn.Sequential( Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size), nn.Linear(patch_dim, dim), ) # 位置编码 # num_patches: (256//32) ** 2=64 # (1, 65, 1024) self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim)) # (1,1,1024) self.cls_token = nn.Parameter(torch.randn(1, 1, dim)) # emb_dropout=0.1 self.dropout = nn.Dropout(emb_dropout) # dim=1024 # depth=6 # heads=16 # dim_head=64 # mlp_dim=2048 self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout) self.pool = pool # 这个函数建立一个输入模块,什么都不做,通常用在神经网络的输入层。这个可以用在残差学习中。 self.to_latent = nn.Identity() # dim=1024 self.mlp_head = nn.Sequential( nn.LayerNorm(dim), nn.Linear(dim, num_classes) ) def forward(self, img, mask = None): # img:[b,3,256,256] # x:[b,64,1024] x = self.to_patch_embedding(img) b, n, _ = x.shape # self.cls_token: [1, 1, dim] # cls_tokens: [b, 1, dim] cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b) # x: [b, 65, 1024] x = torch.cat((cls_tokens, x), dim=1) # x 加上位置编码 x += self.pos_embedding[:, :(n + 1)] x = self.dropout(x) # x: 输入输出维度都是 [b, 65, 1024] x = self.transformer(x, mask) # [b, 1024] x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0] x = self.to_latent(x) return self.mlp_head(x)
下面我们看下 Transformer 的代码, ViT 中的 Transformer 结构中有 Attention 、FeedForward 两个结构。注意此处没有 Decoder 结构,只有 Encoder 。
# dim=1024
# depth=6
# heads=16
# dim_head=64
# mlp_dim=2048
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Residual(PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout))),
Residual(PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout)))
]))
def forward(self, x, mask = None):
for attn, ff in self.layers:
x = attn(x, mask = mask)
x = ff(x)
return x
先看 Attention 。
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
# project_out: True
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
# 计算 q k v 矩阵
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x, mask = None):
# x: [b, 65, 1024]
# h:16
b, n, _, h = *x.shape, self.heads
# chunk: 将 tensor 进行分割成 3 份,如果指定轴的元素被 3 除不尽,那么最后一块的元素个数变少
# qkv: [b, 65, inner_dim * 3]
qkv = self.to_qkv(x).chunk(3, dim = -1)
# q k v: [b, 65, inner_dim]=[b, 65, 16*64]->[b, 16, 65, 64]
# map: 取出 qkv 中的每个值,然后执行 lambda 表达式
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)
# dots: 返回的维度为 [b, 16, 65, 65] ,相当于 q*k.T
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
# 获取最小值,也就相当于 0
mask_value = -torch.finfo(dots.dtype).max
# mask: [1, 8, 8]
if mask is not None:
# pad: 矩阵填充函数
# input: 需要扩充的 tensor ,可以是图像数据,抑或是特征矩阵数据
# pad: 扩充维度,用于预先定义出某维度上的扩充参数
# mode: 扩充方法,’constant‘, ‘reflect’ or ‘replicate’三种模式,分别表示常量,反射,复制
# value: 扩充时指定补充值,但是 value 只在 mode='constant’ 有效,即使用 value 填充在扩充出的新维度位置,而在’reflect’和’replicate’模式下,value不可赋值
# pad 定义:
# 如果参数pad只定义两个参数,表示只对输入矩阵的最后一个维度进行扩充
# 如果参数pad只定义四个参数,前两个参数对最后一个维度有效,后两个参数对倒数第二维有效。
# 如果参数pad定义六个参数,前4个参数完成了在高和宽维度上的扩张,后两个参数则完成了对通道维度上的扩充。
# p1d = (左边填充数, 右边填充数)
# p2d = (左边填充数, 右边填充数, 上边填充数, 下边填充数)
# p3d = (左边填充数, 右边填充数, 上边填充数, 下边填充数, 前边填充数,后边填充数)
mask = F.pad(mask.flatten(1), (1, 0), value = True)
assert mask.shape[-1] == dots.shape[-1], 'mask has incorrect dimensions'
a = rearrange(mask, 'b i -> b () i ()')
b = rearrange(mask, 'b j -> b () () j')
# [b, 1, 65, 1] * [b, 1, 1, 65]=[b, 1, 65, 65]
mask = rearrange(mask, 'b i -> b () i ()') * rearrange(mask, 'b j -> b () () j')
dots.masked_fill_(~mask, mask_value)
del mask
attn = dots.softmax(dim=-1)
# out = attn.v
# [b, 16, 65, 65]*[b, 16, 65, 64]->[b, 16, 65, 64]
out = einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
out = self.to_out(out)
return out
再看 FeedForward 。
- FFN: 两个全链接层,第一个使用激活函数,第二个不使用。
class FeedForward(nn.Module): def __init__(self, dim, hidden_dim, dropout = 0.): super().__init__() self.net = nn.Sequential( nn.Linear(dim, hidden_dim), nn.GELU(), nn.Dropout(dropout), nn.Linear(hidden_dim, dim), nn.Dropout(dropout) ) def forward(self, x): return self.net(x)
残差网络的实现,先执行 fn 操作,然后与输入进行相加。
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(x, **kwargs) + x
归一化的实现,先对输入进行归一化,然后执行 fn 操作
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)