0. 参考资料
1. 概述
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,经过近几年的发展, Transformer 不仅在 NLP 领域有很好的应用,在 CV 领域也得到了快速发展。最初 Transformer 是为了替换 RNN 网络而出现的,因为 RNN 循环神经网络是顺序模型,时间 t 时刻的计算依赖于时间 t-1 时刻的输出,这限制了模型的并行能力;其次顺序计算的过程中信息会丢失。为了解决上述两个问题, Transformer 使用了 attention 机制,将序列中任意两个位置之间的距离缩小为一个常量。;其次它避免了使用顺序结构,因此具有更好的并行性。
2. Transformer
如果把 Transformer 看成一个黑盒的话,那么 Transformer 的结构应该是如下图所示,输入一个句子,输出要翻译的结果。

但实际上,这个黑盒的内部是由一些列 Encode-Decoder 结构组成的,如下图所示:
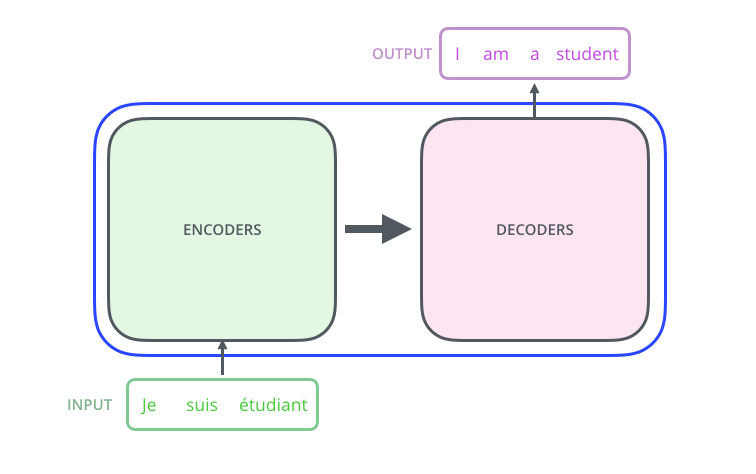
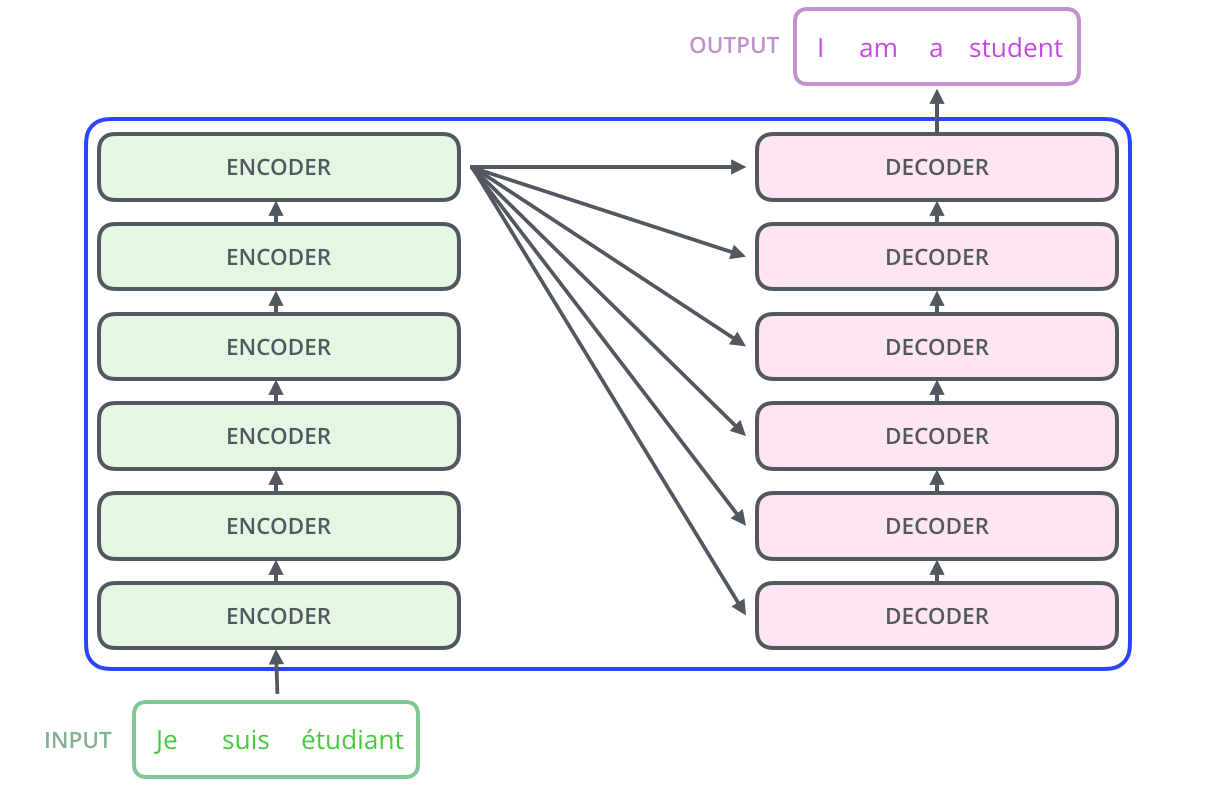
论文中给出了编码器和解码器的个数是 6 个,如下图所示:
2.1. 自注意力机制
自注意力机制是 Transformer 最核心的部分。在介绍自注意力机制之前,我们有必要先来了解一下注意力机制。
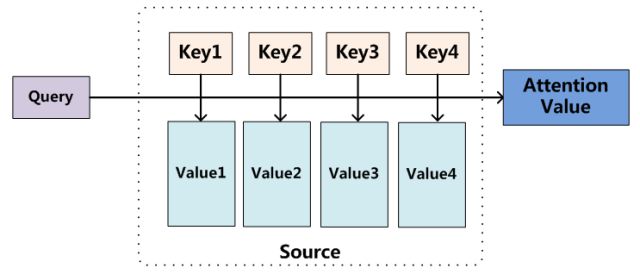
如上图所示,在翻译任务中,是将 Source 语言翻译成 Target 语言,将 Source 中的构成元素想象成是由一系列的 <Key,Value> 数据对构成,此时给定 Target 中的某个元素 Query ,通过计算 Query 和各个 Key 的相似性或者相关性,得到每个 Key 对应 Value 的权重系数,然后对 Value 进行加权求和,即得到了最终的 Attention 数值。所以本质上 Attention 机制是对 Source 中元素的 Value 值进行加权求和,而 Query 和 Key 用来计算对应 Value 的权重系数。即可以将其本质思想改写为如下公式:
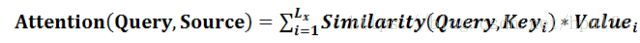
自注意力机制主要是用来表示句子内的关系,比如句子中有一个单词 ‘it’ ,它指代的上下文中的什么东西。在自注意力机制中有 3 个向量,分别是 Query 、 Key 、 Value ,长度都相同,假如是 512 。他们是输入通过点乘 3 个不同的权值矩阵 W 得到,这三个权值矩阵的尺寸都是 512x512 。这三个权值矩阵是网络通过反向传播学习到的。
Query 、 Key 、 Value 矩阵的计算示例图如下所示:
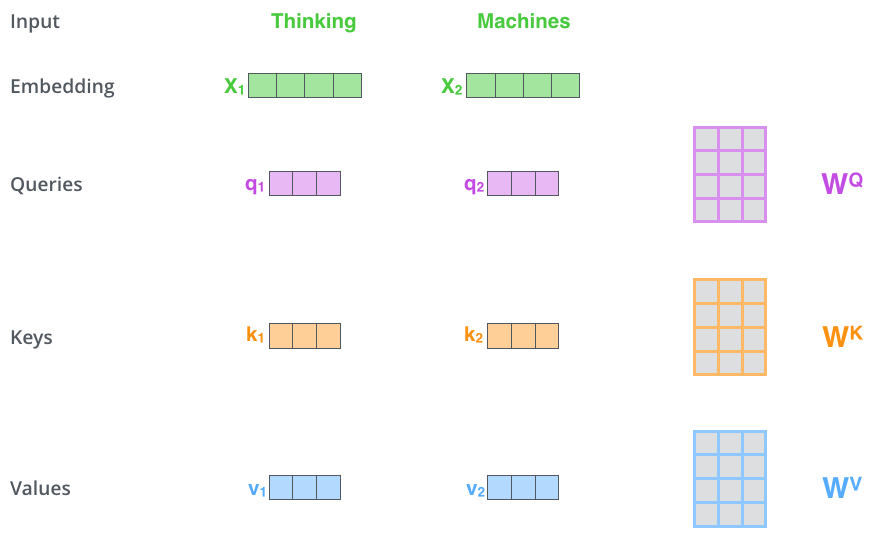
如上图所示,假如输入两个单词,每个单词的词向量的维度为 [1, 512] ,那么两个单词组成的词向量矩阵维度为 [2, 512] ,用词向量分别乘以三个维度为 [512, 512] 的权值矩阵,就得到维度为 [2, 512] 的三个矩阵,分别是 Query 、 Key 、 Value 矩阵。
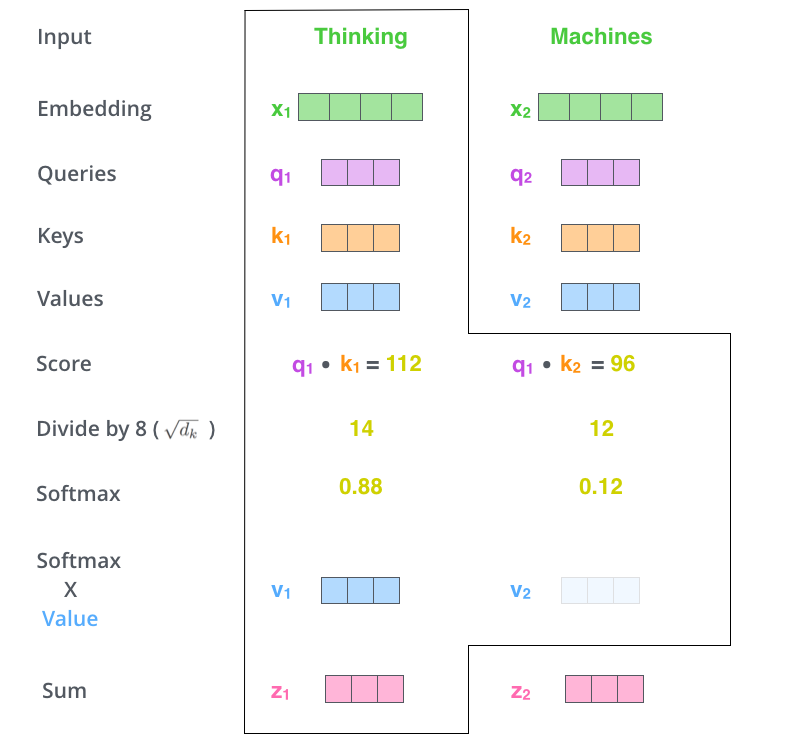
得到 Query(q) 、 Key(k) 、 Value(v) 矩阵后,为每个向量计算 Score , Score = qk.T 。得到的 Score 的维度为 [2, 2] 。然后对 Score 除以 Query 矩阵维度的平方根后进行 softmax 激活,得到维度为 [2, 2] 的矩阵,最后用该维度为 [2, 2] 矩阵点乘 v 矩阵,得到矩阵 Z ,维度为 [2, 512] 。上述 Score 除以 Query 矩阵维度的平方根是为了防止 qk.T 的数值会随着维度的增大而增大,所以要除以该值,相当于归一化的效果。具体流程如下图所示:
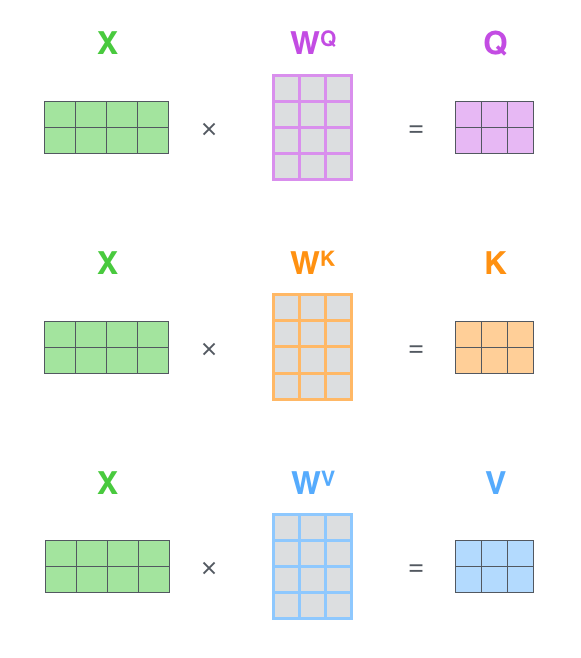
Query 、 Key 、 Value 矩阵的计算流程如下图所示:
矩阵 Z 的计算流程如下图所示:
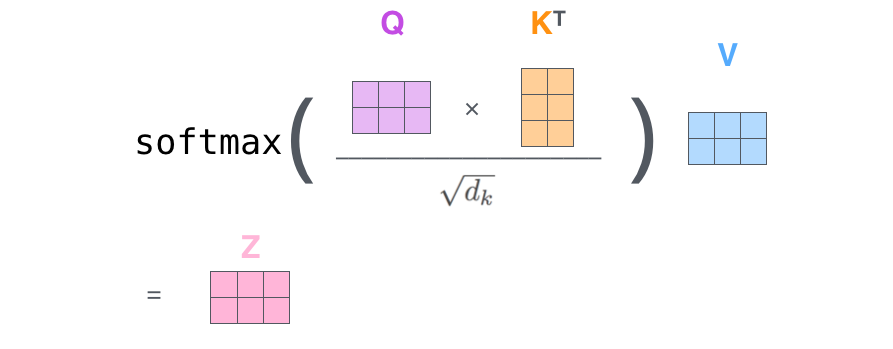
这里还要提一下带 masked 的注意力机制,它在 Transformer 的 Decoder 模块中使用, masked 的意思是使 attention 只会关注已经产生的序列,防止预测时不会受到未来的信息干扰。
了解了自注意力机制是如何工作的,再看自注意力机制的输出计算公式就很好理解了,如下图所示:
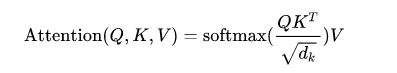
下面看自注意力机制的代码实现。我们首先看下自注意力机制的框架图,如下图所示,自注意力机制的实现代码就是对这张图的翻译过程。
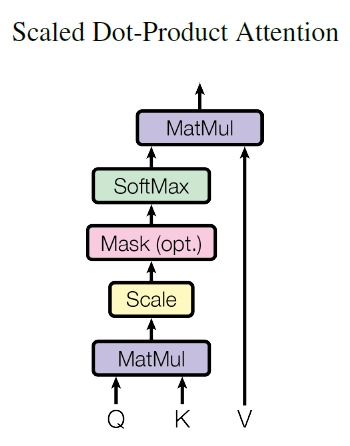
- self.temperature: 起到归一化作用
- k.transpose: 将 k 变成 k.T ,由于数据是一个 batch 输入的,所以用 transpose 将 2 和 3 个维度进行交换
- mask: 带 masked 的注意力机制。
- masked_fill: 将 mask 数组中为 0 位置的 attn 值设为 -1e9 ,作用是将 mask 为 0 的位置值屏蔽
class ScaledDotProductAttention(nn.Module): ''' Scaled Dot-Product Attention ''' def __init__(self, temperature, attn_dropout=0.1): super().__init__() self.temperature = temperature self.dropout = nn.Dropout(attn_dropout) def forward(self, q, k, v, mask=None): attn = torch.matmul(q / self.temperature, k.transpose(2, 3)) if mask is not None: attn = attn.masked_fill(mask == 0, -1e9) attn = self.dropout(F.softmax(attn, dim=-1)) output = torch.matmul(attn, v) return output, attn
Query,Key,Value 的概念取自于信息检索系统,当你在某电商平台搜索某件商品时,你在搜索引擎上输入的内容便是 Query ,然后搜索引擎根据 Query 为你匹配 Key (例如商品的种类,颜色,描述等),然后根据 Query 和 Key 的相似度得到匹配的内容(Value)。
self-attention 中的 Q,K,V 也是起着类似的作用,在矩阵计算中,点积是计算两个矩阵相似度的方法之一,因此 qk.T 进行相似度的计算。接着便是根据相似度进行输出的匹配,这里使用了加权匹配的方式,而权值就是 query 与 key 的相似度。
2.2. 多头自注意力机制
多头自注意力机制,简单理解是词与词之间的关系的产生可能是多种多样的。假如 head=8 ,则实际上使用 8 组不同的权值矩阵 W 分别计算 8 组 Query 、 Key 、 Value 矩阵,最后得到 8 组不同的 Z 值,将他们在列维度上进行拼接,最后将得到新的特征矩阵送入全链接层得到最终的输出 Z 。多头注意力机制实际上时将权值矩阵由 [512, 512] 分成 [512, 8*64] ,最终计算的维度与自注意力机制计算的结果维度是一样的 。计算过程如下图所示:
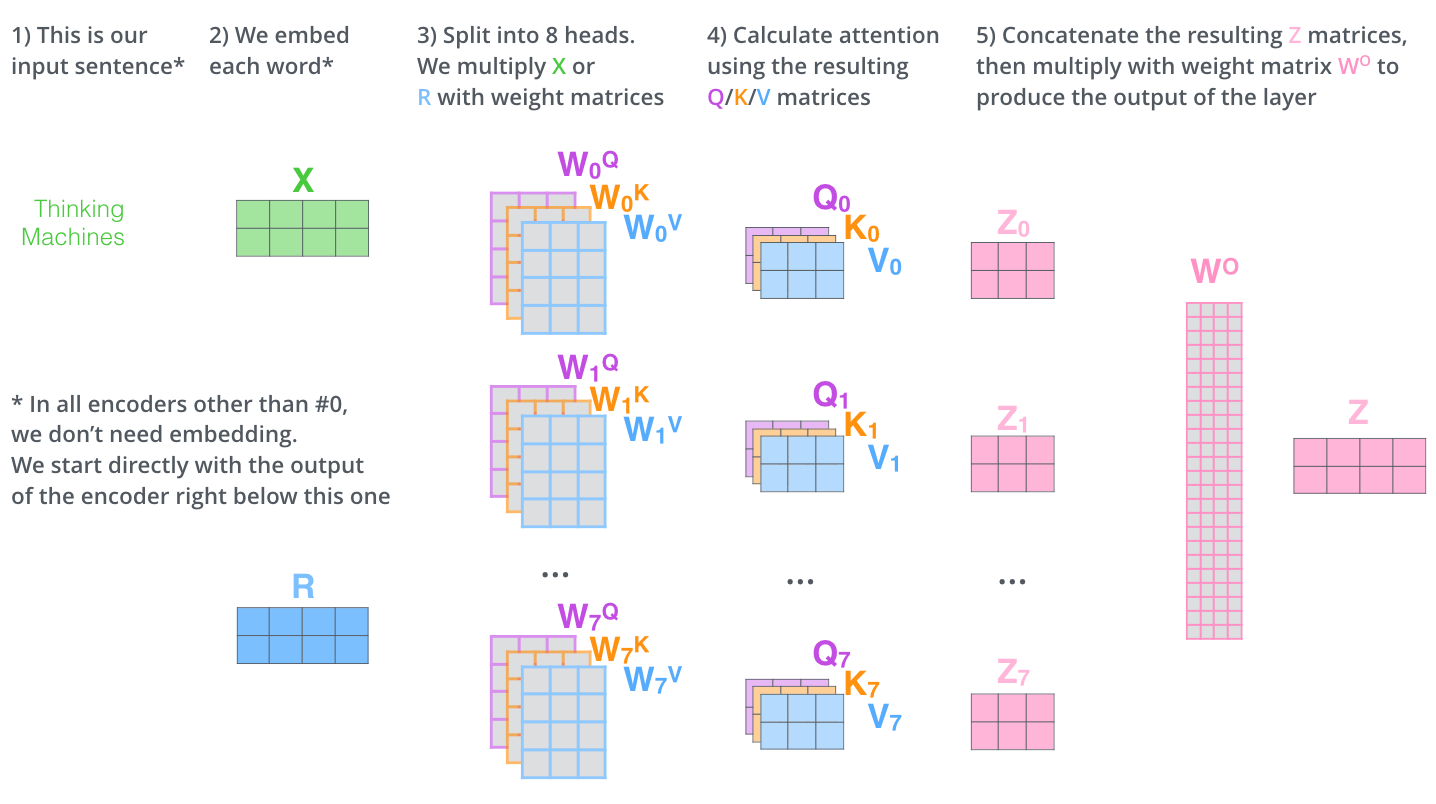
下面我们看一下多头注意力机制的代码实现:
- n_head: 多头注意力,默认是 8 头
- d_k, d_v: 转换矩阵的维度,默认是 64 维。 q 矩阵和 k 矩阵维度相同
- d_model: 输入是由 Word2Vec 等词嵌入方法将输入语料转化成特征向量,向量维度默认是 512
- self.w_qs self.w_ks self.w_vs: 输入的特征向量分别乘上三个不同的转换矩阵得到 embedding 。
- self.fc: 使用转换矩阵调整维度,将维度调整到 d_model ,这里的输出就是前面介绍的 Z 矩阵。
- temperature: 值为 d_k ** 0.5 ,因为 qk.T 的数值会随着 dimension 的增大而增大,所以要除以 dimension 的平方根,相当于归一化的效果。
- self.attention: 上文提到的注意力机制。
- self.layer_norm: Layer Normalization 后面介绍。
class MultiHeadAttention(nn.Module): def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1): super().__init__() self.n_head = n_head self.d_k = d_k self.d_v = d_v self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False) self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False) self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False) self.fc = nn.Linear(n_head * d_v, d_model, bias=False) self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5) self.dropout = nn.Dropout(dropout) self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
前向传播函数:
- residual: 将输入保存,用来计算残差。
- 计算三个权值矩阵, q k v 。NLP 模型输入的数据维度为 [batch_size, seq_len, input_dim] ,其中, seq_len 表示 batch 中每一个序列的长度, input_dim 表示每个序列中的每一个单词的 embedding ,这里的 input_dim 就等于 d_model 。进入全链接层后,输出的维度为 [batch_size, seq_len, output_dim] ,这里的 output_dim 就是 n_head * d_k 。这里又将维度进行了转换,变为 [batch_size, seq_len, n_head, d_k] 。
- 通过 transpose 将 q k v 维度变为 [batch_size, n_head, seq_len, d_k] ,矩阵 q 和 v 施加注意力机制后得到 Z 矩阵形状为 [batch_size, n_head, seq_len, seq_len] ,得到的矩阵 Z 再与 v 进行点乘,形状变为 [batch_size, n_head, seq_len, d_k]
- 通过注意力机制计算 Z ,这里的 Z 存储在 q 中。
- 将 Z 值的维度在变为输入时的维度,以便进行残差计算,维度为 [batch_size, seq_len, n_head * d_k]
- 使用 self.fc 将维度调整到 d_model
- 最后将计算残差后的值进行 LN 计算。
def forward(self, q, k, v, mask=None): d_k, d_v, n_head = self.d_k, self.d_v, self.n_head sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1) residual = q q = self.w_qs(q).view(sz_b, len_q, n_head, d_k) k = self.w_ks(k).view(sz_b, len_k, n_head, d_k) v = self.w_vs(v).view(sz_b, len_v, n_head, d_v) # Transpose for attention dot product: b x n x lq x dv q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2) if mask is not None: mask = mask.unsqueeze(1) # For head axis broadcasting. q, attn = self.attention(q, k, v, mask=mask) q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1) q = self.dropout(self.fc(q)) q += residual q = self.layer_norm(q) return q, attn
2.4. 位置编码
我们知道像 RNN 这种序列模型,天生就具有位置信息,但是 Transformer 是如何提供这种能力的呢?答案是位置编码。也就是在词向量中加入位置信息。那么如何增加位置信息呢?论文中提到有两种方式,一种是根据数据学习,另一种是手动设计编码规则,论文中作者采用了第二种方式。通常位置编码是一个长度为 d 维的特征向量,维度与词向量相同,这样便于和词向量进行相加操作。位置编码的计算公式如下图所示:
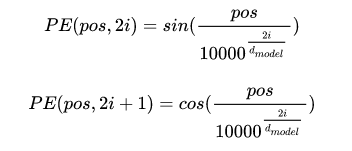
上式中 pos 表示单词的位置, i 表示单词的维度。准确来说 2i 和 2i + 1 表示单词的维度, i 的取值范围是 [0, d/2] 。作者提到,这样设计是因为 NLP 任务中,除了单词的绝对位置,单词的相对位置也非常重要。根据下图公式可知,任意位置 p+k 都可以被位置 k 的线性函数表示,这为模型捕捉单词之间的相对位置关系提供了非常大的便利。
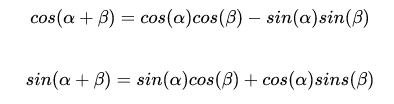
位置编码代码实现:
- n_position: 表示 token 在 sequence 中的位置
- d_hid: 表示了 Positional Encoding 的维度
class PositionalEncoding(nn.Module): def __init__(self, d_hid, n_position=200): super(PositionalEncoding, self).__init__() self.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid)) def _get_sinusoid_encoding_table(self, n_position, d_hid): ''' Sinusoid position encoding table ''' # TODO: make it with torch instead of numpy def get_position_angle_vec(position): return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)] sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)]) sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 return torch.FloatTensor(sinusoid_table).unsqueeze(0) def forward(self, x): return x + self.pos_table[:, :x.size(1)].clone().detach()
2.5. FFN
FFN 即是 Feed Forward Neural Network 的简称,其实就是两个全链接层。第一个全链接层使用 relu 激活函数,第二个全链接层使用线性激活函数。第二个全链接层的输出经过 dropout 后与输入进行残差计算,最后使用 LN 进行标准化。代码如下:
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid)
self.w_2 = nn.Linear(d_hid, d_in)
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return x
2.7. Layer Normolization
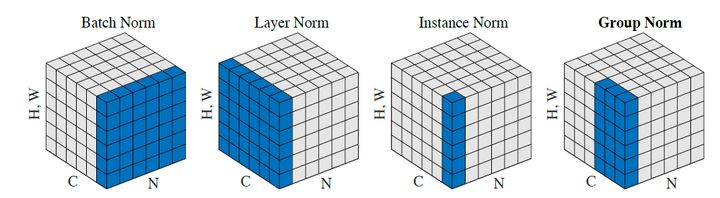
BN 是取不同样本的同一个通道的特征做归一化, BN 是按照样本数计算归一化统计量的,当样本数很少时,样本的均值和方差不能反映全局的统计分布息,所以基于少量样本的 BN 的效果会变得很差,在一些场景中,比如说硬件资源受限,在线学习等场景, BN 是非常不适用的; LN 则是取的是同一个样本的不同通道做归一化,即根据样本的特征数做归一化。 LayerNorm 中不会像 BatchNorm 那样跟踪统计全局的均值方差,因此 train() 和 eval() 对 LayerNorm 没有影响。 LN 和 BN 的区别可以看下图:
LayerNorm 有三个参数,含义分别是:
- normalized_shape: 输入尺寸
- eps: 归一化时加在分母上防止除零
- elementwise_affine: 如果设为 False ,则 LayerNorm 层不含有任何可学习参数。如果设为 True (默认是 True) 则会包含可学习参数 weight 和 bias ,用于仿射变换,即对输入数据归一化到均值 0 方差 1 后,乘以 weight ,加上 bias 。
2.8. Encoder-Decoder 模块
了解了上述各个子模块的原理之后, Transformer 整体结构也就掌握了,先贴一张 Transformer 整体框架图,如下图所示,图中左侧方框框起来的是 Encoder ,右侧方框框起来的是 Decoder 。
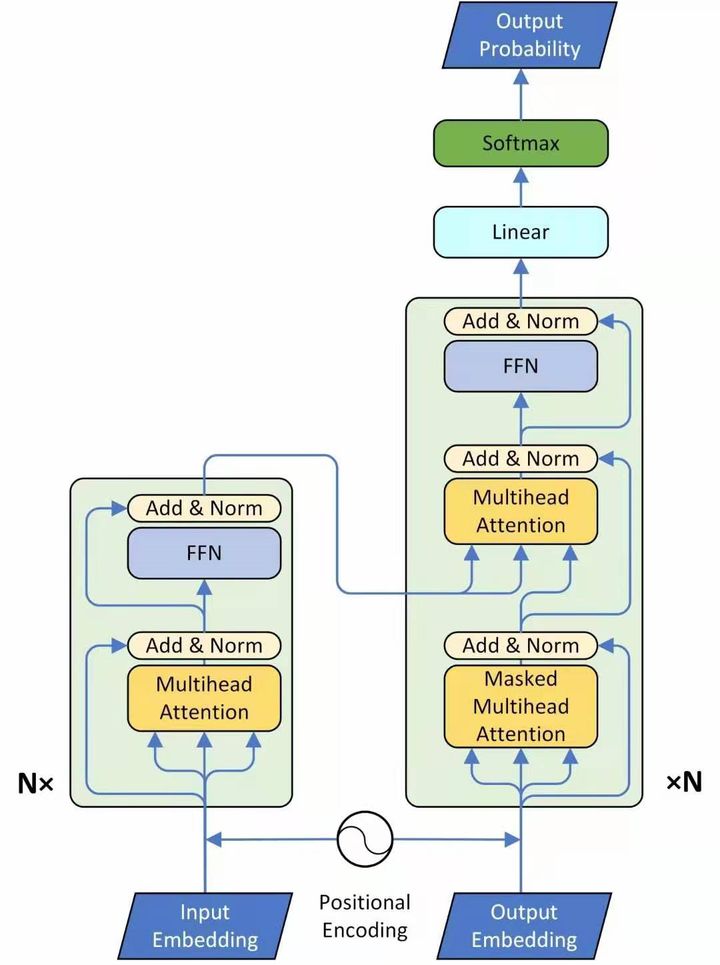
这里主要分析下网络的输入和输出,首先看框架图的左侧 Encoder 模块, Encoder 模块的输入就是词向量与位置编码的和。 Encoder 的输出当作 Decoder 输入的一部分进入 Decoder 模块。
Decoder 的输入包括 2 部分,一部分来自下方,是前一个 timestep 的输出,再加上一个表示位置的 Positional Encoding ;另一部分来自 Encoder 的输出,作为中间的 attention 的 key 和 value ,而中间的 attention 的 query 来自第一个 attention 的输出。 Decoder 的输出是对应 i 位置的输出词的概率分布。 Decoder 的解码不是一次把所有序列解出来的,而是像 RNN 一样一个一个解出来的,因为要用上一个位置的输入当作 attention 的 query 。
Encoder 代码实现如下:
class EncoderLayer(nn.Module):
''' Compose with two layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(EncoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(self, enc_input, slf_attn_mask=None):
enc_output, enc_slf_attn = self.slf_attn(
enc_input, enc_input, enc_input, mask=slf_attn_mask)
enc_output = self.pos_ffn(enc_output)
return enc_output, enc_slf_attn
Decoder 代码实现如下:
class DecoderLayer(nn.Module):
''' Compose with three layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(DecoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(
self, dec_input, enc_output,
slf_attn_mask=None, dec_enc_attn_mask=None):
dec_output, dec_slf_attn = self.slf_attn(
dec_input, dec_input, dec_input, mask=slf_attn_mask)
dec_output, dec_enc_attn = self.enc_attn(
dec_output, enc_output, enc_output, mask=dec_enc_attn_mask)
dec_output = self.pos_ffn(dec_output)
return dec_output, dec_slf_attn, dec_enc_attn