0. 参考资料
- Vision Transformer 超详细解读 (原理分析+代码解读) (一)
- attention-is-all-you-need-pytorch
- transformer 在 CV 中的应用(一) Transformer 介绍
1. 概述
DETR 目标监测网络是 Facebook 提出的目标监测网络,它是 transformer 在目标检测网络中的首次尝试。相比之前使用 anchor 的目标检测网络, DETR 是一种 anchor free 的目标检测网络,网络最终输出为无序预测集合 (set prediction) 。作者认为像 Faster-RCNN 网络这种设置一大堆的 anchor ,然后基于 anchor 进行分类和回归是属于代理做法,而目标检测任务应该是输出无序集合。那么 DETR 网络结构到底是怎样?它又是如何训练的呢?本文主要介绍 DETR 网络结构以及网络训练流程。
2. 网络结构
DETR 的网络结构由两部分组成, backbone 和 transformer 。
if __name__ == '__main__':
main(args)
def main(args):
model, criterion, postprocessors = build_model(args)
def build_model(args):
return build(args)
def build(args):
backbone = build_backbone(args)
transformer = build_transformer(args)
model = DETR(
backbone,
transformer,
num_classes=num_classes,
num_queries=args.num_queries,
aux_loss=args.aux_loss,
)
在介绍网络结构之前先介绍下 DETR 网络输入数据的打包格式 NestedTensor 。
- 该函数输入是一个 batch 数据,包括图像信息和图像标签
- zip 将图像信息和图像标签分开存储
- batch[0]: 取出图像信息,将图像信息进行预处理
def collate_fn(batch): batch = list(zip(*batch)) batch[0] = nested_tensor_from_tensor_list(batch[0]) return tuple(batch)
nested_tensor_from_tensor_list 该函数有点类似 letterbox 函数的作用。
- _max_by_axis: 找出一个 batch 图像中各个维度数的最大值,为了兼容不同图像大小
- tensor_list: 一个 batch 的数据,维度为 [b, c, h, w]
- tensor: 存放预处理后的数据,维度为 [b, c, h, w] ,先初始化为 0 ,然后将源图像的数据拷贝进去
- mask: 维度为 [b, h, w] ,先初始化为 1 ,然后将原图像的位置设为 0
- zip: 按 batch 维度进行提取数据,并设置 tensor 和 mask
- NestedTensor: 该类对 tensor 和 mask 进行封装
def nested_tensor_from_tensor_list(tensor_list: List[Tensor]): # TODO make this more general if tensor_list[0].ndim == 3: if torchvision._is_tracing(): # nested_tensor_from_tensor_list() does not export well to ONNX # call _onnx_nested_tensor_from_tensor_list() instead return _onnx_nested_tensor_from_tensor_list(tensor_list) # TODO make it support different-sized images max_size = _max_by_axis([list(img.shape) for img in tensor_list]) # min_size = tuple(min(s) for s in zip(*[img.shape for img in tensor_list])) batch_shape = [len(tensor_list)] + max_size b, c, h, w = batch_shape dtype = tensor_list[0].dtype device = tensor_list[0].device tensor = torch.zeros(batch_shape, dtype=dtype, device=device) mask = torch.ones((b, h, w), dtype=torch.bool, device=device) for img, pad_img, m in zip(tensor_list, tensor, mask): pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img) m[: img.shape[1], :img.shape[2]] = False else: raise ValueError('not supported') return NestedTensor(tensor, mask)
NestedTensor 类比较简单,提供 decompose 函数获取 tensor 和 mask 。 repr 函数重定义了实例化对象的基本信息,调用 print(NestTensor) 时打印该函数的输出。
class NestedTensor(object):
def __init__(self, tensors, mask: Optional[Tensor]):
self.tensors = tensors
self.mask = mask
def to(self, device):
# type: (Device) -> NestedTensor # noqa
cast_tensor = self.tensors.to(device)
mask = self.mask
if mask is not None:
assert mask is not None
cast_mask = mask.to(device)
else:
cast_mask = None
return NestedTensor(cast_tensor, cast_mask)
def decompose(self):
return self.tensors, self.mask
def __repr__(self):
return str(self.tensors)
2.1 backbone
DETR 网络中的 backbone 模块中包括两个部分,特征提取网络和位置编码。
- arg.slr_backbone=1e-5 ,所以 train_backbone=True
- return_interm_layers: 该变两用于语义分割
- args.backbone: resnet50
- args.dilation: False
def build_backbone(args): position_embedding = build_position_encoding(args) train_backbone = args.lr_backbone > 0 return_interm_layers = args.masks backbone = Backbone(args.backbone, train_backbone, return_interm_layers, args.dilation) model = Joiner(backbone, position_embedding) model.num_channels = backbone.num_channels return model
我们先看特征提取网络,特征提取网络使用的是 resnet50 。
- num_channels: resnet50 输出的特征图通道维度是 2048
class Backbone(BackboneBase): def __init__(self, name: str, train_backbone: bool, return_interm_layers: bool, dilation: bool): backbone = getattr(torchvision.models, name)( replace_stride_with_dilation=[False, False, dilation], pretrained=is_main_process(), norm_layer=FrozenBatchNorm2d) num_channels = 512 if name in ('resnet18', 'resnet34') else 2048 super().__init__(backbone, train_backbone, num_channels, return_interm_layers)
BackboneBase 是 Backbone 基类,该类提供了前向传播函数。
- IntermediateLayerGetter: 该函数的作用是将 return_layers 之前的层保留,之后的层全部丢弃。
- 前向传播中, self.body 输出 OrderedDict 类型,保存特征图。
- 遍历 OrderedDict ,取出 mask ,对 mask 进行下采样 32 倍,因为 backbone 将图像下采样了 32 倍。
- m[None]: [b,h,w]->[1,b,h,w] ,这么做的原因是 interpolate 只能接收 4 维的输入。
- size: 是特征图的大小,也就是将 mask 重新 resize 到特征图的大小。
- out: 将下采样的数据和 mask 保存到 NestedTensor 中。
class BackboneBase(nn.Module): def __init__(self, backbone: nn.Module, train_backbone: bool, num_channels: int, return_interm_layers: bool): super().__init__() for name, parameter in backbone.named_parameters(): if not train_backbone or 'layer2' not in name and 'layer3' not in name and 'layer4' not in name: parameter.requires_grad_(False) if return_interm_layers: return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"} else: return_layers = {'layer4': "0"} self.body = IntermediateLayerGetter(backbone, return_layers=return_layers) self.num_channels = num_channels def forward(self, tensor_list: NestedTensor): xs = self.body(tensor_list.tensors) out: Dict[str, NestedTensor] = {} for name, x in xs.items(): m = tensor_list.mask assert m is not None mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0] out[name] = NestedTensor(x, mask) return out
下面看下位置编码的实现。位置编码官方实现了两种,一种是固定位置编码,另一种是自学习位置编码,这里就介绍固定位置编码。
位置编码要考虑 x, y 两个方向,图像中任意一个点 (h, w) 有一个位置,这个位置编码长度为 256 ,前 128 维代表 h 的位置编码, 后 128 维代表 w 的位置编码,把这两个 128 维的向量拼接起来就得到一个 256 维的向量,它代表 (h, w) 的位置编码。位置编码的计算公式如下图所示:
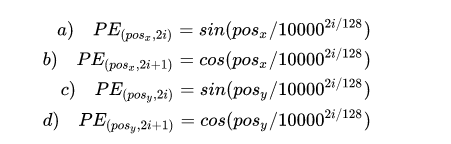
- args.hidden_dim = 256
- args.position_embedding=sine
def build_position_encoding(args): N_steps = args.hidden_dim // 2 if args.position_embedding in ('v2', 'sine'): position_embedding = PositionEmbeddingSine(N_steps, normalize=True) return position_embedding - num_pos_feats=128
- normalize=True
- not_mask: mask 在之前已经将合法的图像位置设为了 0 ,取反后将合法图像位置设为了 1 。
- y_embed, x_embed: 一开始计算 h, w 维度的累加和,然后除以累加后的和进行归一化处理。 cumsum 的功能是返回给定 axis 上的累加和
- y_embed[:, -1:, :] 和 x_embed[:, :, -1:]: 取 y_embed 和 x_embed 累加后的最大值
- eps: 为了防止除数为 0
- dim_t: 先创建一个 1 维的长度维 128 的向量,根据位置编码的公式计算正余玄函数的参数 10000^(2i/128)
- pos_x, pos_y: 先对 y_embed 和 x_embed 升维,维度变为 [b, h, w, 1] ,运用广播机制除以 dim_t 维度变为 [b, h, w, 128]
- 根据位置计算 sin 和 cos 值,使用 stack 进行拼接,拼接维度维 dim=4 ,注意数组的切片步长是 2 ,因此维度变为了 [b, h, w, 64, 2] ,最后使用 flatten(3) 再将维度变为 [b, h, w, 128]
- pos: 最后使用 torch.cat 将 pos_x, pos_y 拼接在一起, dim=3 ,维度变为 [b, h, w, 256] ,然后使用 permute(0, 3, 1, 2) 将维度变为 [b, 256, h, w]
class PositionEmbeddingSine(nn.Module): def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None): super().__init__() self.num_pos_feats = num_pos_feats self.temperature = temperature self.normalize = normalize if scale is not None and normalize is False: raise ValueError("normalize should be True if scale is passed") if scale is None: scale = 2 * math.pi self.scale = scale def forward(self, tensor_list: NestedTensor): x = tensor_list.tensors # mask: [b, h, w] mask = tensor_list.mask assert mask is not None not_mask = ~mask y_embed = not_mask.cumsum(1, dtype=torch.float32) x_embed = not_mask.cumsum(2, dtype=torch.float32) if self.normalize: eps = 1e-6 y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device) dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats) pos_x = x_embed[:, :, :, None] / dim_t pos_y = y_embed[:, :, :, None] / dim_t pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3) pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3) pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2) return pos
Joiner 类将特征提取网络和位置编码进行封装。
- init 函数将特征提取网络和位置编码添加到 nn.Sequential 结构中。
- self[0]: 指只特征提取网络
- self[1]: 指 position_embedding
- xs: 字典类型,值的类型为 NestedTensor , BackboneBase 的前向传播的输出
- self1: 对特征图进行位置编码
- out: 链表,保存 NestedTensor 类型,维度为 [b, 2048, h, w]
- pos: 链表,保存维度 [b, 256, h, w]
class Joiner(nn.Sequential): def __init__(self, backbone, position_embedding): super().__init__(backbone, position_embedding) def forward(self, tensor_list: NestedTensor): xs = self[0](tensor_list) out: List[NestedTensor] = [] pos = [] for name, x in xs.items(): out.append(x) pos.append(self[1](x).to(x.tensors.dtype)) return out, pos
总结一下 backbone ,首先使用 resnet50 网络对输入图像数据进行特征提取,数据维度由 [batch, 3, H, W] -> [batch, C, H1, W1] ,其中 C=2048 , H1=H/32 W1=W/32 。然后根据特征图生成位置编码,维度为 [batch, 256, H1, W1] 。
2.2. transformer
DETR 中的 transformer ,包括 Encoder 和 Decoder 两个部分,网络结构如下图所示:
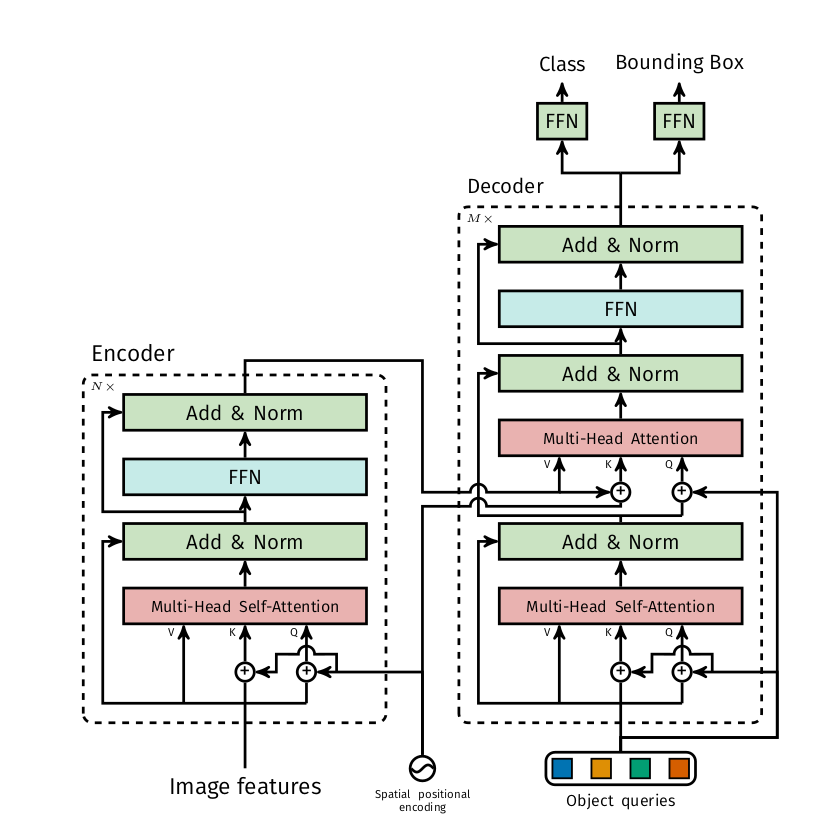
下面看 Transformer 的实现。
def build_transformer(args):
return Transformer(
d_model=args.hidden_dim,
dropout=args.dropout,
nhead=args.nheads,
dim_feedforward=args.dim_feedforward,
num_encoder_layers=args.enc_layers,
num_decoder_layers=args.dec_layers,
normalize_before=args.pre_norm,
return_intermediate_dec=True,
)
- d_model=256
- dim_feedforward=2048
- normalize_before=False
- encoder_norm=None
- return_intermediate_dec=True: 是否保存 Decoder 的中间层用于计算损失, True 表示会保存。
class Transformer(nn.Module): def __init__(self, d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=2048, dropout=0.1, activation="relu", normalize_before=False, return_intermediate_dec=False): super().__init__() encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout, activation, normalize_before) encoder_norm = nn.LayerNorm(d_model) if normalize_before else None self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm) decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout, activation, normalize_before) decoder_norm = nn.LayerNorm(d_model) self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm, return_intermediate=return_intermediate_dec) self._reset_parameters() self.d_model = d_model self.nhead = nhead def _reset_parameters(self): for p in self.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p)
先看 Encoder 。 Encoder 中包含多个 TransformerEncoderLayer 。
- Encoder 由两部分组成,多头自注意力机制和 FFN
- with_pos_embed: 该函数用来增加残差
- DETR 网络的只有 q 和 k 需要增加位置编码
class TransformerEncoderLayer(nn.Module): def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu", normalize_before=False): super().__init__() self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout) self.linear1 = nn.Linear(d_model, dim_feedforward) self.dropout = nn.Dropout(dropout) self.linear2 = nn.Linear(dim_feedforward, d_model) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(dropout) self.dropout2 = nn.Dropout(dropout) self.activation = _get_activation_fn(activation) self.normalize_before = normalize_before def with_pos_embed(self, tensor, pos: Optional[Tensor]): return tensor if pos is None else tensor + pos def forward_post(self, src, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None): # q 和 k 加上位置编码 q = k = self.with_pos_embed(src, pos) # 多头注意力机制 src2 = self.self_attn(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0] # 残差 src = src + self.dropout1(src2) # 标准化 src = self.norm1(src) # FFN: 第一个全链接接后跟 relu 激活函数,第二个全链接无激活函数 src2 = self.linear2(self.dropout(self.activation(self.linear1(src)))) # 残差 src = src + self.dropout2(src2) # 边准化 src = self.norm2(src) return src def forward(self, src, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None): return self.forward_post(src, src_mask, src_key_padding_mask, pos)
TransformerEncoder 就是重复多次 TransformerEncoderLayer 。
- src: [hxw, b, 256]
- output: 第一次是 src ,之后都是上一个的输出
- mask: None
- src_key_padding_mask: [b, hxw]
class TransformerEncoder(nn.Module): def __init__(self, encoder_layer, num_layers, norm=None): super().__init__() self.layers = _get_clones(encoder_layer, num_layers) self.num_layers = num_layers # self.norm = None self.norm = norm def forward(self, src, mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None): output = src for layer in self.layers: output = layer(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask, pos=pos) if self.norm is not None: output = self.norm(output) return output
下面介绍 Decoder 。 Decoder 中包含多个 TransformerEncoderLayer 。
- Decoder 由三部分构成,多头自注意力机制、多头注意力机制、 FNN
- 第一个多头自注意力机制的 q 和 k 加上 Object query
- 第二个多头注意力机制的 k 和 v 来自 Encoder ,且 k 加上了位置编码, q 来自第一个多头自注意力的输出,并且加上了 Object query
class TransformerDecoderLayer(nn.Module): def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu", normalize_before=False): super().__init__() self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout) self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout) self.linear1 = nn.Linear(d_model, dim_feedforward) self.dropout = nn.Dropout(dropout) self.linear2 = nn.Linear(dim_feedforward, d_model) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.norm3 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(dropout) self.dropout2 = nn.Dropout(dropout) self.dropout3 = nn.Dropout(dropout) self.activation = _get_activation_fn(activation) self.normalize_before = normalize_before def with_pos_embed(self, tensor, pos: Optional[Tensor]): return tensor if pos is None else tensor + pos def forward_post(self, tgt, memory, tgt_mask: Optional[Tensor] = None, memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None, query_pos: Optional[Tensor] = None): # q 和 k 加上 Object query q = k = self.with_pos_embed(tgt, query_pos) # 多头自注意力机制 tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)[0] # 残差 tgt = tgt + self.dropout1(tgt2) # 标准化 tgt = self.norm1(tgt) # 多头注意力机制,之前的 tgt 加上 Object query tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos), key=self.with_pos_embed(memory, pos), value=memory, attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0] # 残差 tgt = tgt + self.dropout2(tgt2) 标准化 tgt = self.norm2(tgt) # FFN tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt)))) # 残差 tgt = tgt + self.dropout3(tgt2) # 标准化 tgt = self.norm3(tgt) return tgt def forward(self, tgt, memory, tgt_mask: Optional[Tensor] = None, memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None, query_pos: Optional[Tensor] = None): return self.forward_post(tgt, memory, tgt_mask, memory_mask, tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
TransformerDecoder 就是重复多次 TransformerDecoderLayer 。
- memory: 是 encoder 的输出
- tgt: [100, 4, 256] 初始全是 0
- memory_mask: None
- tgt_key_padding_mask: None
- memory_key_padding_mask: [b, hxw]
- pos: 与 encoder 相同的位置编码
- query_pos: [100, 4, 256]
class TransformerDecoder(nn.Module): def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False): super().__init__() self.layers = _get_clones(decoder_layer, num_layers) self.num_layers = num_layers self.norm = norm self.return_intermediate = return_intermediate def forward(self, tgt, memory, tgt_mask: Optional[Tensor] = None, memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None, query_pos: Optional[Tensor] = None): output = tgt intermediate = [] for layer in self.layers: output = layer(output, memory, tgt_mask=tgt_mask, memory_mask=memory_mask, tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=memory_key_padding_mask, pos=pos, query_pos=query_pos) # self.return_intermediate=True # 保存 Decoder 中间层 if self.return_intermediate: intermediate.append(self.norm(output)) # self.norm is not None if self.norm is not None: output = self.norm(output) if self.return_intermediate: intermediate.pop() intermediate.append(output) if self.return_intermediate: return torch.stack(intermediate) return output.unsqueeze(0)
介绍了 Encoder 和 Decoder 后,在来看 Transformer 类的前向传播函数:
- src: [b, 256, H/32, H/32]
- mask: [b, h, w]
- query_embed: Parameter ,可训练参数
- pos_embed: 位置编码 [b, 256, h, w] [100, 256]
def forward(self, src, mask, query_embed, pos_embed): # flatten NxCxHxW to HWxNxC bs, c, h, w = src.shape # src: [b, 256, h, w]->[b, 256, hxw]->[hxw, b, 256] src = src.flatten(2).permute(2, 0, 1) # pos_embed: [b, 256, h, w]->[b, 256, hxw]->[hxw, b, 256] pos_embed = pos_embed.flatten(2).permute(2, 0, 1) # query_embed: 是 embed.weight # [100, 256] -> [100, 1, 256] # repeat: [100, 1, 256]->[100, 4, 256] query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1) # mask: [b, h, w]->[b, hxw] mask = mask.flatten(1) # tgt: [100, 4, 256] tgt = torch.zeros_like(query_embed) memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed) hs = self.decoder(tgt, memory, memory_key_padding_mask=mask, pos=pos_embed, query_pos=query_embed) return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
总结一下,首先, backbone 对输入的每一个 batch 的图像进行通道维度的拉伸以及宽高维度的压缩;
位置编码要考虑 x, y 两个方向,图像中任意一个点 (h, w) 有一个位置,这个位置编码长度为 256 ,前 128 维代表 h 的位置编码, 后 128 维代表 w 的位置编码,把这两个 128 维的向量拼接起来就得到一个 256 维的向量,它代表 (h, w) 的位置编码,另外,注意位置编码作用位置, DETR 在每个 Encoder 的输入都加入了位置编码,且只对 Query 和 Key 使用,即只与 Query 和 Key 相加,不与 Value 进行相加,对于 Decoder 的第二个多头注意力机制的 k 也加入了位置编码的信息;
Encoder 的输入和输出维度都是 [H1xW1, batch, 256] 。
Decoder 的输入由多个部分组成, Encoder 的输出、 object queries 、上一个 Decoder 的输出。 Decoder 的输入一开始初始化成维度为 [100, batch, 256] 维的全部元素都为 0 的张量,和 Object queries 加在一起之后充当第 1 个 multi-head self-attention 的 Query 和 Key 。第一个 multi-head self-attention 的 Value 为 Decoder 的输入,也就是全0的张量。每个 Decoder 的第 2 个 multi-head self-attention ,它的 Key 和 Value 来自 Encoder 的输出张量,维度为 [H1xW1, batch, 256] ,其中 Key 值还进行位置编码。 Query 值一部分来自第 1 个 Add and Norm 的输出,维度为 [100, batch, 256] 的张量,另一部分来自 Object queries ,充当可学习的位置编码。所以,第 2 个 multi-head self-attention 的 Key 和 Value 的维度为 [H1xW1, batch, 256] ,而 Query 的维度为 [100, batch, 256] 。
Decoder 的输出为 [batch, 100, 256] 。
object queries 维度为 [100, batch, 256] ,类型为 nn.Embedding 说明这个张量是学习得到的, Object queries 充当的其实是位置编码的作用,只不过它是可以学习的位置编码。
2.3. DETR 模型定义
DETR 类将之前介绍的 backbone 和 transformer 组装在一起。
- self.input_proj: 对主干网络输出的特征图进行通道压缩 [b, 2048, H/32, H/32] -> [b, 256, H/32, H/32]
- self.class_embed: 得到类别预测信息
- self.bbox_embed: 得到边界框预测信息
- features, pos: 都是链表,分别保存 NestedTensor 和位置编码
- 在 Decoder 网络中保存了每一个 Decoder 的输出,所以这里的 hs 的维度为 [6, b, 100, 256]
class DETR(nn.Module): def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False): super().__init__() # num_queries=100 self.num_queries = num_queries self.transformer = transformer hidden_dim = transformer.d_model # hidden_dim=256 self.class_embed = nn.Linear(hidden_dim, num_classes + 1) self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3) self.query_embed = nn.Embedding(num_queries, hidden_dim) self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1) self.backbone = backbone self.aux_loss = aux_loss def forward(self, samples: NestedTensor): if isinstance(samples, (list, torch.Tensor)): samples = nested_tensor_from_tensor_list(samples) # features: 链表,保存 NestedTensor 类型 # pos: 链表,保存维度 [b, 256, h, w] features, pos = self.backbone(samples) src, mask = features[-1].decompose() assert mask is not None # transformer: 输出元组,分别为 Decoder 和 Encoder 的输出 # torch.nn.Parameter 是继承自 torch.Tensor 的子类,其主要作用是作为 nn.Module 中的可训练参数使用。它与 torch.Tensor 的区别就是 nn.Parameter 会自动被认为是 module 的可训练参数,即加入到 parameter() 这个迭代器中去;而 module 中非 nn.Parameter() 的普通 tensor 是不在 parameter 中的。 hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0] # hs:[b, 100, 256] # [b, 100, class+1] outputs_class = self.class_embed(hs) # [b, 100, 4] outputs_coord = self.bbox_embed(hs).sigmoid() out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]} # 是否计算 Decoder 层的损失 if self.aux_loss: out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord) return out # 这个装饰器向编译器表明,应该忽略一个函数或方法,并用引发异常来替换它。这允许您在模型中保留与TorchScript不兼容的代码,同时仍然导出模型。 # 遍历除最后一个 Decoder 的输出外的另外 5 个 Decoder 层的输出。 @torch.jit.unused def _set_aux_loss(self, outputs_class, outputs_coord): return [{'pred_logits': a, 'pred_boxes': b} for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
3. 网络训练
在上一章网络结构中我们只到网络最终输出的结果是类别预测信息,维度为 [b, 100, class+1] ;边界框预测信息,维度为 [b, 100, 4] ,那么这些预测信息该如何与 GT 值进行匹配来计算网络损失,从而达到训练模型的效果呢?
作者在训练中引入了匈牙利算法来计算最优匹配,匈牙利算法是用来计算二分图的最优匹配问题,我们可以认为网络预测的结果对应二分图的左边, GT 值对应二分图的右边,根据二分图的定义,左边各个节点之间不能相连,右边各个节点之间不能相连,只能左边节点与右边节点相连。两边进行匹配的原则是什么呢?是使左边和右边最相近的两个节点进行相连,在 DETR 网络中也就是两边节点损失函数最小的进行匹配,匈牙利算法是计算每一个预测值与每一 GT 值都进行计算损失函数,然后找到相似度最接近的进行匹配,然后在反向传播过程中,更新网络参数使得匹配后的两个节点的损失逐渐变小。
def build(args):
matcher = build_matcher(args)
criterion = SetCriterion(num_classes, matcher=matcher, weight_dict=weight_dict,
eos_coef=args.eos_coef, losses=losses)
我们首先看下匹配的流程。
- args.set_cost_class = 1
- args.set_cost_bbox = 5
- args.set_cost_giou = 2
def build_matcher(args): return HungarianMatcher(cost_class=args.set_cost_class, cost_bbox=args.set_cost_bbox, cost_giou=args.set_cost_giou)
负责预测值与 GT 值匹配的是 HungarianMatcher 类。
- 匈牙利算法匹配使用的代价参数由三个部分组成,类别损失、 L1 Loss 损失、 GIOU 损失,详细的计算过程请看下面代码的注释。
class HungarianMatcher(nn.Module): def __init__(self, cost_class: float = 1, cost_bbox: float = 1, cost_giou: float = 1): super().__init__() self.cost_class = cost_class self.cost_bbox = cost_bbox self.cost_giou = cost_giou assert cost_class != 0 or cost_bbox != 0 or cost_giou != 0, "all costs cant be 0" # output: 类别预测和边界框预测 # target: 标签 @torch.no_grad() def forward(self, outputs, targets): bs, num_queries = outputs["pred_logits"].shape[:2] # We flatten to compute the cost matrices in a batch # start_dim=0, end_dim=1 # n 个预测器,每个预测器输出预测的类别概率 out_prob = outputs["pred_logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes] # n 个预测器,每个预测器输出预测边界框 out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4] # Also concat the target labels and boxes # 目标中类别索引和边界框 tgt_ids = torch.cat([v["labels"] for v in targets]) # tgt_bbox: [N, 4] tgt_bbox = torch.cat([v["boxes"] for v in targets]) # NLL: negative log likelihood loss 负对数似然损失 # Compute the classification cost. Contrary to the loss, we don't use the NLL, # but approximate it in 1 - proba[target class]. # The 1 is a constant that doesn't change the matching, it can be ommitted. # 从所有类别输出中,找出预测类别结果中,类别 ID 是 tgt_ids 的预测结果 # 对于每个预测结果,把目前 gt 里面有的所有类别值提取出来,其余值不需要参与匹配 # 行:取每一行;列:只取 tgt_ids 对应的 N 列 # 匈牙利算法的作用是选出哪一个预测器使预测的结果的误差最小 # 这样计算的目的是在所有预测器中,预测为某一类别时,哪一个预测器预测的结果误差最小,误差最小的就与标签进行匹配 # 这只是匈牙利算法 cost 的一部分,假如某一张图片有 3 个目标,匈牙利算法要计算网络输出的 100 个预测结果中,预测成这三个目标时哪个预测结果使误差最小,这只是匈牙利算法 cost 的一部分, 下面的 L1 loss 和 iou 是同样的道理。 # cost_class: [batch_size * num_queries, N] cost_class = -out_prob[:, tgt_ids] # Compute the L1 cost between boxes # x1 (Tensor) – input tensor of shape B×P×M . # x2 (Tensor) – input tensor of shape B×R×M . # output (Tensor) – will have shape B×P×R # out_bbox: [batch_size * num_queries, 4] # tgt_bbox: [N, 4] # cost_bbox: [batch_size * num_queries, N] cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1) # Compute the giou cost betwen boxes # cost_giou: [batch_size * num_queries, N] cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox)) # Final cost matrix # [batch_size * num_queries, N] C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou # # [batch_size * num_queries, N] -> # [batch_size , num_queries, N] C = C.view(bs, num_queries, -1).cpu() # 计算一个 batch 中每一张图片中目标的大小 sizes = [len(v["boxes"]) for v in targets] # torch.split(tensor, split_size_or_sections, dim=0) # 按照每张图像的 target 个数划分,计算每张图片的匹配情况 # i 表示 batch 的索引 # c[i]: 表示某一张图片中 100 个预测器与目标进行匹配的所有损失值,匈牙利算法要计算出最优的匹配,使损失值最小 # indices: 是一个 tuple 类型,包含两个元素,第一个元素是匹配的行索引,第二个元素是匹配的列索引 indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))] # 把匹配的行列索引转换成 tensor 类型,然后添加到列表里,每一项存储一个 tuple 类型, tuple 里有两个元素,匹配的行索引和列索引 return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
下面看 DETR 计算损失函数的类 SetCriterion 。
- self.eos_coef: 背景类别的相对权重,这里是 0.1 ,这么设置的原因我的理解是背景的数目远远大于有物体的数目,所以计算损失时降低背景的损失的权重。
- SetCriterion 先使用 HungarianMatcher 计算模型预测值与 gt 之间的匹配关系,然后对匹配后的结果计算损失。
- 损失的计算包括 label 损失,对应函数是 loss_labels ; boxes 损失,对应函数是 loss_boxes ; cardinality 损失,对应函数是 loss_cardinality ; cardinality 损失是计算预测有物体的个数的绝对损失,值是为了记录,不参与反向传播。
- aux_outputs: 计算 Decoder 辅助损失,也就是前 5 个 Decoder 输出的损失
- 具体损失计算过程清参看代码中的注释。
# # 监测每一对匹配了的 gt 和预测值 class SetCriterion(nn.Module): def __init__(self, num_classes, matcher, weight_dict, eos_coef, losses): super().__init__() self.num_classes = num_classes self.matcher = matcher self.weight_dict = weight_dict self.eos_coef = eos_coef # losses = ['labels', 'boxes', 'cardinality'] self.losses = losses empty_weight = torch.ones(self.num_classes + 1) empty_weight[-1] = self.eos_coef self.register_buffer('empty_weight', empty_weight) def loss_labels(self, outputs, targets, indices, num_boxes, log=True): """Classification loss (NLL) targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes] """ assert 'pred_logits' in outputs src_logits = outputs['pred_logits'] # idx: batch_idx, src_idx: 记录每张图片中匹配成功的预测器索引 idx = self._get_src_permutation_idx(indices) # target_classes_o: 保存每一张图片中,匹配到的类别索引 target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)]) # 初始化 target_classes 全为背景 # [bs, 100] target_classes = torch.full(src_logits.shape[:2], self.num_classes, dtype=torch.int64, device=src_logits.device) # 设置匹配的预测器对应的类别 target_classes[idx] = target_classes_o # 计算类别损失 # src_logits: [bs, 100, 92] -> [bs, 92, 100] ,这里做维度变换的原因是 cross_entropy 里的 log_softmax 函数作用的维度是 dim=1 ,所以将预测类别维度放到 dim=1 位置 # target_classes: [bs, 100]: 每个预测器匹配后的类别,大部分是背景 loss_ce = F.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight) losses = {'loss_ce': loss_ce} if log: # TODO this should probably be a separate loss, not hacked in this one here losses['class_error'] = 100 - accuracy(src_logits[idx], target_classes_o)[0] return losses @torch.no_grad() def loss_cardinality(self, outputs, targets, indices, num_boxes): """ Compute the cardinality error, ie the absolute error in the number of predicted non-empty boxes This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients """ # 计算预测有物体的个数的绝对损失,值是为了记录,不参与反向传播 pred_logits = outputs['pred_logits'] device = pred_logits.device # tgt_lengths: 每张图像中目标的个数 tgt_lengths = torch.as_tensor([len(v["labels"]) for v in targets], device=device) # Count the number of predictions that are NOT "no-object" (which is the last class) # 计算预测类别概率最大的索引不是背景的所有预测 # pred_logits:[bs, 100, num_class] # (pred_logits.argmax(-1) != pred_logits.shape[-1] - 1): [bs, 100] # card_pred: [bs], 保存每张图像中,预测有目标的个数 card_pred = (pred_logits.argmax(-1) != pred_logits.shape[-1] - 1).sum(1) card_err = F.l1_loss(card_pred.float(), tgt_lengths.float()) losses = {'cardinality_error': card_err} return losses def loss_boxes(self, outputs, targets, indices, num_boxes): """Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4] The target boxes are expected in format (center_x, center_y, w, h), normalized by the image size. """ assert 'pred_boxes' in outputs idx = self._get_src_permutation_idx(indices) # outputs['pred_boxes']: [bs, 100, 4] # src_boxes: [N, 4] src_boxes = outputs['pred_boxes'][idx] target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0) loss_bbox = F.l1_loss(src_boxes, target_boxes, reduction='none') losses = {} losses['loss_bbox'] = loss_bbox.sum() / num_boxes # generalized_box_iou: 两两计算 iou # torch.diag: 只取匹配后的 iou loss_giou = 1 - torch.diag(box_ops.generalized_box_iou( box_ops.box_cxcywh_to_xyxy(src_boxes), box_ops.box_cxcywh_to_xyxy(target_boxes))) losses['loss_giou'] = loss_giou.sum() / num_boxes return losses def loss_masks(self, outputs, targets, indices, num_boxes): """Compute the losses related to the masks: the focal loss and the dice loss. targets dicts must contain the key "masks" containing a tensor of dim [nb_target_boxes, h, w] """ assert "pred_masks" in outputs src_idx = self._get_src_permutation_idx(indices) tgt_idx = self._get_tgt_permutation_idx(indices) src_masks = outputs["pred_masks"] src_masks = src_masks[src_idx] masks = [t["masks"] for t in targets] # TODO use valid to mask invalid areas due to padding in loss target_masks, valid = nested_tensor_from_tensor_list(masks).decompose() target_masks = target_masks.to(src_masks) target_masks = target_masks[tgt_idx] # upsample predictions to the target size src_masks = interpolate(src_masks[:, None], size=target_masks.shape[-2:], mode="bilinear", align_corners=False) src_masks = src_masks[:, 0].flatten(1) target_masks = target_masks.flatten(1) target_masks = target_masks.view(src_masks.shape) losses = { "loss_mask": sigmoid_focal_loss(src_masks, target_masks, num_boxes), "loss_dice": dice_loss(src_masks, target_masks, num_boxes), } return losses def _get_src_permutation_idx(self, indices): # permute predictions following indices # indices 是一个列表,列表中的每一项表示每一张图片的预测值与真实值的匹配情况 # src: 表示行索引,表示哪个预测器,形状为 (m, ) # batch_idx: 记录每个目标在这个 batch 中的哪张图片,例如 [0,0,0,1,1,1,1,2,2,3] # 表示,图片 0 有三个目标,图片 2 有 4 个目标,以此类推。 batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)]) # src_idx: 记录每张图片中匹配成功的预测器索引,与 batch_idx 相对应 src_idx = torch.cat([src for (src, _) in indices]) return batch_idx, src_idx def _get_tgt_permutation_idx(self, indices): # permute targets following indices # 计算列索引 batch_idx = torch.cat([torch.full_like(tgt, i) for i, (_, tgt) in enumerate(indices)]) tgt_idx = torch.cat([tgt for (_, tgt) in indices]) return batch_idx, tgt_idx # losses = ['labels', 'boxes', 'cardinality'] def get_loss(self, loss, outputs, targets, indices, num_boxes, **kwargs): loss_map = { 'labels': self.loss_labels, 'cardinality': self.loss_cardinality, 'boxes': self.loss_boxes, 'masks': self.loss_masks } assert loss in loss_map, f'do you really want to compute {loss} loss?' return loss_map[loss](outputs, targets, indices, num_boxes, **kwargs) # outputs: 字典,包含类别预测 pred_logits ,边界框预测 pred_boxes 和 aux_outputs # targets: 标签,包含类别和边界框信息 def forward(self, outputs, targets): """ This performs the loss computation. Parameters: outputs: dict of tensors, see the output specification of the model for the format targets: list of dicts, such that len(targets) == batch_size. The expected keys in each dict depends on the losses applied, see each loss' doc """ # 取出 pred_logits 和 pred_boxes outputs_without_aux = {k: v for k, v in outputs.items() if k != 'aux_outputs'} # Retrieve the matching between the outputs of the last layer and the targets # indices: 列表,每一项存储一个 tuple 类型,tuple里有两个元素,匹配的行索引和列索引 indices = self.matcher(outputs_without_aux, targets) # Compute the average number of target boxes accross all nodes, for normalization purposes # 计算一个 batch 中目标的总和 num_boxes = sum(len(t["labels"]) for t in targets) num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device) if is_dist_avail_and_initialized(): torch.distributed.all_reduce(num_boxes) num_boxes = torch.clamp(num_boxes / get_world_size(), min=1).item() # Compute all the requested losses losses = {} # self.losses = ['labels', 'boxes', 'cardinality'] for loss in self.losses: losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes)) # In case of auxiliary losses, we repeat this process with the output of each intermediate layer. if 'aux_outputs' in outputs: for i, aux_outputs in enumerate(outputs['aux_outputs']): indices = self.matcher(aux_outputs, targets) for loss in self.losses: if loss == 'masks': # Intermediate masks losses are too costly to compute, we ignore them. continue kwargs = {} if loss == 'labels': # Logging is enabled only for the last layer kwargs = {'log': False} l_dict = self.get_loss(loss, aux_outputs, targets, indices, num_boxes, **kwargs) l_dict = {k + f'_{i}': v for k, v in l_dict.items()} losses.update(l_dict) return losses
DETR 网络结构及实现就介绍到这。