1. 概述
MobileNet 是 谷歌 2017 提出的用于移动设备上的轻量级神经网络。那么为什么 MobileNet 是如何做到在不影响模型精度的条件下,大幅减少模型参数的呢?答案是深度可分离卷积。在随后的两年谷歌又推出了 V2 和 V3 版本。
2. 深度可分离卷积
深度可分离卷积就是将普通卷积拆分成为一个深度卷积和一个逐点卷积。
2.1. 深度卷积
对于标准卷积,输入一个 12×12×3 的一个图像,经过一个卷积核大小为 5×5×3 的卷积得到一个 8×8×1 的输出特征图。如果有 256 个卷积核,我们将会得到一个 8×8×256 的输出特征图。
而对于深度卷积,是将卷积核拆分成为单通道形式,在不改变输入特征图像的深度的情况下,对每一通道进行卷积操作,这样就得到了和输入特征图通道数一致的输出特征图。输入 12×12×3 的特征图,经过 5×5×1×3 的深度卷积之后,得到了 8×8×3 的输出特征图。输入和输出的维度是不变的。
这样就会有一个问题,通道数太少,特征图的维度太少,能获取到足够的有效信息吗?这时逐点卷积就该登场了。
2.2. 逐点卷积
逐点卷积就是 1×1 卷积。主要作用就是对特征图进行升维和降维。
在深度卷积的过程中,我们得到了 8×8×3 的输出特征图,我们用 256 个 1×1×3 的卷积核对输入特征图进行卷积操作,输出的特征图和标准的卷积操作一样都是 8×8×256 了。
以上述为例,这里我们对比一下标准卷积和深度可分离卷积参数量的大小,先看一下标准卷积:
5×5×3×256 = 19200
对于深度可分离卷积参数量为:
5x5x1x3 + 1x1x3x256 = 843
很明显,深度可分离卷积的参数量相比普通卷积的参数量有了大幅下降。
3. MobileNet V1
3.1. 网络结构
MobileNet V1 网络主干结构如下图所示:
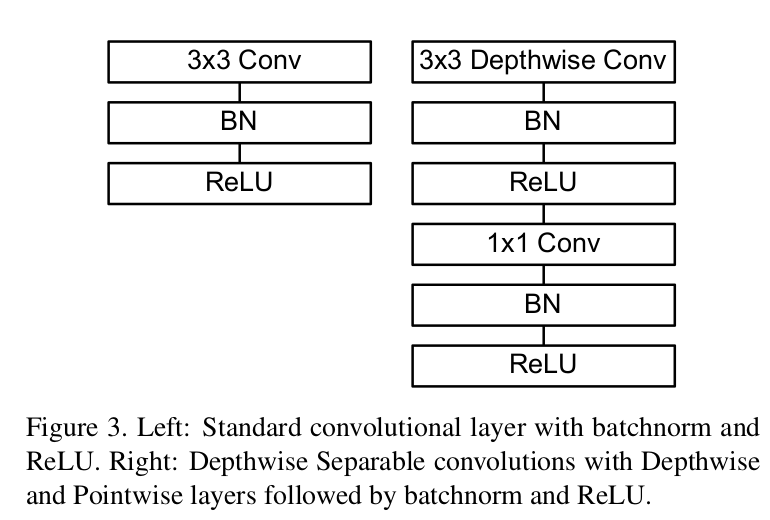
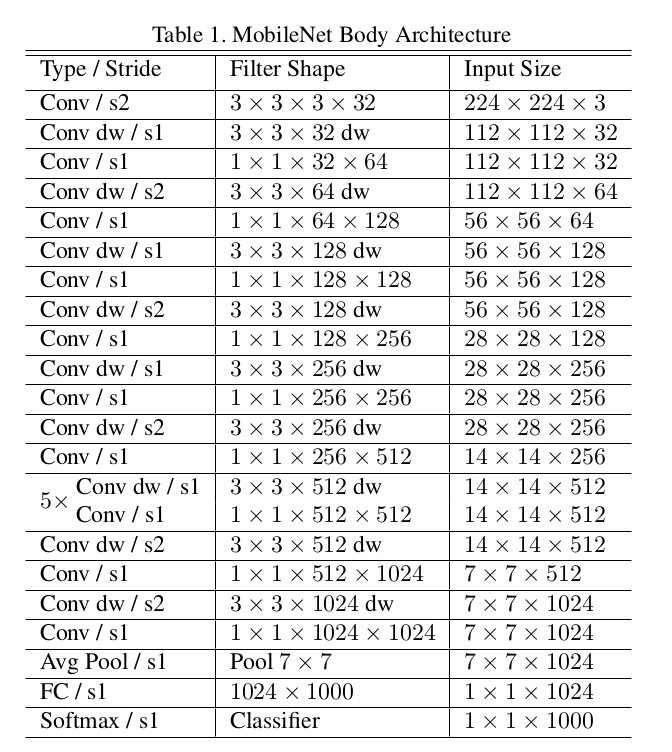
MobileNet V1 网络结构组成如下图所示,其中 s1 表示步长为 1 , s2 表示步长为 2 , Conv 表示普通卷积网络, Conv dw 表示深度可分离卷积网络中的深度卷积。
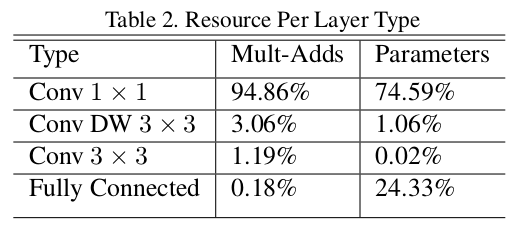
MobileNet V1 网络参数和计算量分布:
3.1. 网络实现
- 我们从下面代码可以看出 MobileNetV1 网络的结构就是普通卷积和深度可分离卷积的堆叠。
- conv_bn 和 conv_dw 分别实现了普通卷积和深度可分离卷积,输入参数分别为输入通道数、输出通道数和步长。
- 深度可分离卷积中的深度卷积将 groups 设为 inp 。
- 注意: conv_dw 函数实现了网络结构里的 Conv dw 和 Conv 两个结构
class MobileNetV1(nn.Module): def __init__(self): super(Net, self).__init__() def conv_bn(inp, oup, stride): return nn.Sequential( nn.Conv2d(inp, oup, 3, stride, 1, bias=False), nn.BatchNorm2d(oup), nn.ReLU(inplace=True) ) def conv_dw(inp, oup, stride): return nn.Sequential( nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False), nn.BatchNorm2d(inp), nn.ReLU(inplace=True), nn.Conv2d(inp, oup, 1, 1, 0, bias=False), nn.BatchNorm2d(oup), nn.ReLU(inplace=True), ) self.model = nn.Sequential( conv_bn( 3, 32, 2), conv_dw( 32, 64, 1), conv_dw( 64, 128, 2), conv_dw(128, 128, 1), conv_dw(128, 256, 2), conv_dw(256, 256, 1), conv_dw(256, 512, 2), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 1024, 2), conv_dw(1024, 1024, 1), nn.AvgPool2d(7), ) self.fc = nn.Linear(1024, 1000) def forward(self, x): x = self.model(x) x = x.view(-1, 1024) x = self.fc(x) return x
4. MobileNet V2
4.1. 网络结构
在 MobileNet V1 网络中,利用 3×3 的深度可分离卷积提取特征,然后利用 1×1 的卷积来扩张通道。这样网络结构既能减少不小的参数量、计算量,提高了网络运算速度,又能的得到一个接近于标准卷积的还不错的结果,看起来是很美好的。但是,实际使用的时候, 发现深度卷积部分的卷积核比较容易训废掉,即训完之后发现深度卷积训出来的卷积核有不少是空的。作者认为这是 ReLU 激活函数导致的。

从上图看出,当 n = 2,3 时,与 Input 相比有很大一部分的信息已经丢失了。而当 n = 15 到 30 时,还是有相当多的地方被保留了下来。也就是说,对低维度做 ReLU 运算,很容易造成信息的丢失。而在高维度进行 ReLU 运算的话,信息的丢失则会很少。这就解释了为什么深度卷积的卷积核有不少是空。既然是 ReLU 导致的上述问题,那么就将 ReLU 替换成线性激活函数。于是就有了 Linear bottleneck 网络结构。
Linear bottleneck 网络结构中将原来深度可分离卷积中的最后的 ReLU 换成线性激活函数。
现在还有个问题是,深度卷积本身没有改变通道的能力,来的是多少通道输出就是多少通道。如果来的通道很少的话,深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要对通道数进行扩张。既然我们已经知道 PW 逐点卷积也就是 1×1 卷积可以用来升维和降维,那就可以在 DW 深度卷积之前使用 PW 卷积进行升维,再在一个更高维的空间中进行卷积操作来提取特征。
MobileNetV2 网络还有一个改进就是采用像 ResNet 网络那样的残差结构,论文中称为倒残差网络结构。
MobileNet V2 网络主干结构如下图所示:
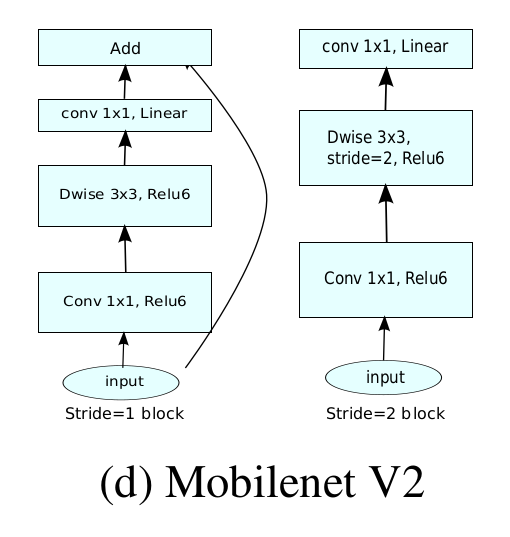
MobileNet V2 网络组成结构如下图所示。其中 t 表示输入通道的扩张系数; n 表示该模块的重复次数; c 表示输出通道数; s 表示 stride ;注意 stride=2 只在网络结构的第一个第一个卷积层使用,其他的层还是使用 stride=1 。
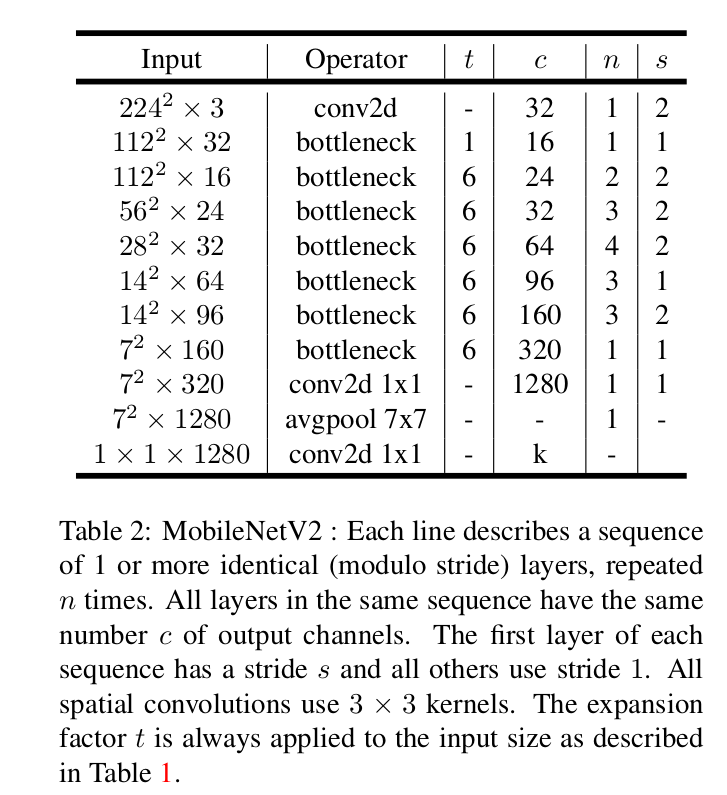
4.2. 网络实现
定义 ConvBNReLU 网络结构,包括卷积层、标准还、激活函数。注意这里的激活函数为 ReLU6 。当 groups 不是 1 时是深度卷积,为 1 时是普通卷积。
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
定义倒残差网络。
- 输入参数为:输入通道、输出通道、步长、扩张系数
- hidden_channel: 表示增加了扩张系数后的卷积网络的输出
- 当 stride=1 并且 输入通道等于输出通道时使用残差边
- 如果扩张系数不等于 1 ,先使用 1x1 卷积对输入特征升维
- 紧接着是深度卷积, groups=hidden_channel
- 然后在使用 1x1 卷积进行降维
- 最后使用 BN 层进行归一化
- 注意:倒残差结构的最后一层没有加激活函数
- 正向传播时,如果有残差边则将输入与网络的输出相加
class InvertedResidual(nn.Module): def __init__(self, in_channel, out_channel, stride, expand_ratio): super(InvertedResidual, self).__init__() hidden_channel = in_channel * expand_ratio self.use_shortcut = stride == 1 and in_channel == out_channel layers = [] if expand_ratio != 1: # 1x1 pointwise conv layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1)) layers.extend([ # 3x3 depthwise conv ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel), # 1x1 pointwise conv(linear) nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False), nn.BatchNorm2d(out_channel), ]) self.conv = nn.Sequential(*layers) def forward(self, x): if self.use_shortcut: return x + self.conv(x) else: return self.conv(x)
_make_divisible 函数保证输出的数可以整除 divisor ,原因是在大多数硬件中, size 可以被 d = 8, 16, … 整除的矩阵乘法比较块,因为这些 size 符合处理器单元的对齐位宽。
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
MobileNetV2 网络实现代码如下,根据网络结构组成那张图很容易看懂下面的代码。
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(3, input_channel, stride=2))
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, 1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
5. MobileNet V3
5.1. 网络结构
MobileNet V3 相比较 MobileNet V2 引入了轻量级注意力机制以及使用 h-swish 激活函数。
MobileNet V3 包含两个网络: small 和 large ,二者没有明显的区别,只是 bneck 的次数和通道数有一些差异。
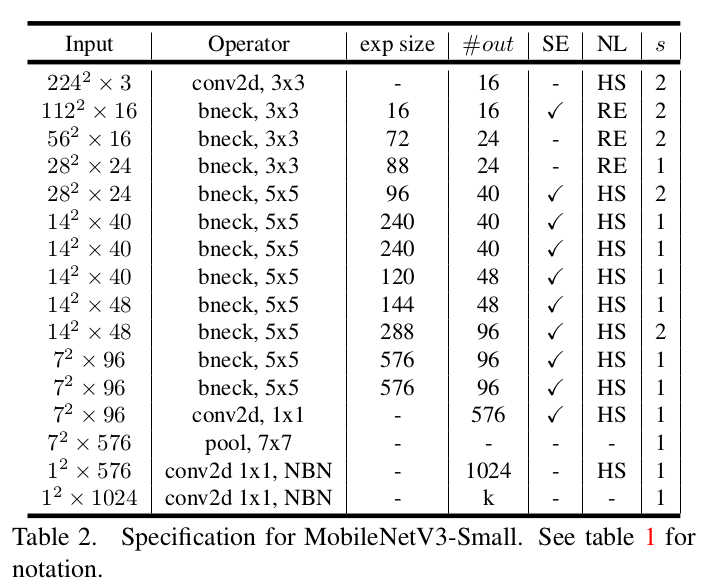
small 网络的组成结构如下图所是:
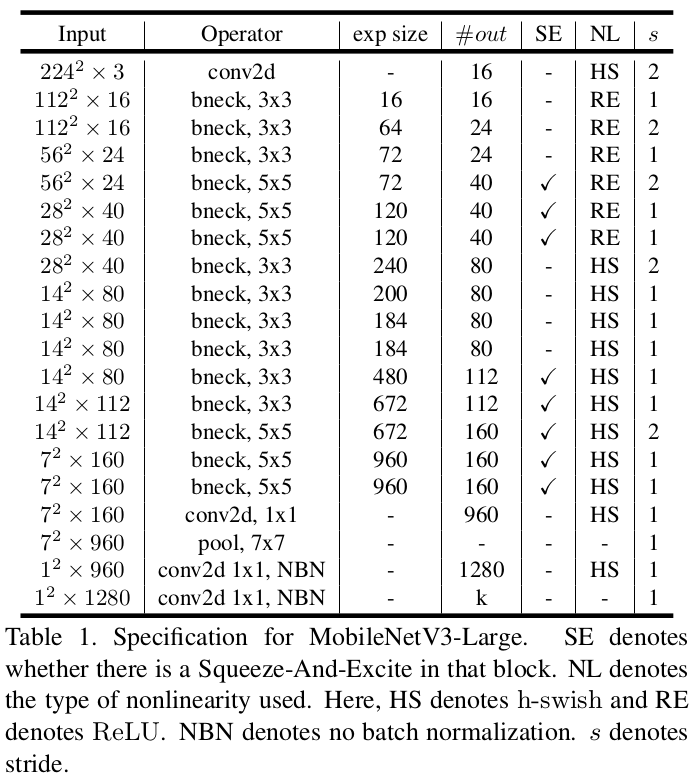
large 网络的组成结构如下图所是:
上述网络组成结构中的定义如下:
- 第一列 Input 代表 MobileNetV3 每个特征层的输入的 shape ;
- 第二列 Operator 代表每次特征层即将经历的 block 结构,在 MobileNetV3 中,特征提取经过了许多的 bneck 结构;
- 第三、四列分别代表了 bneck 内倒残差结构上升后的通道数以及输出通道数。
- 第五列 SE 代表了是否在这一层引入注意力机制。
- 第六列 NL 代表了激活函数的种类, HS 代表 h-swish , RE 代表 RELU 。
- 第七列 s 代表了每一次 block 结构所用的步长。
h-swish 激活函数公式如下图所是:
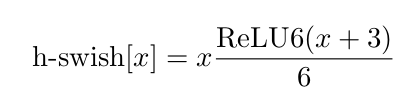
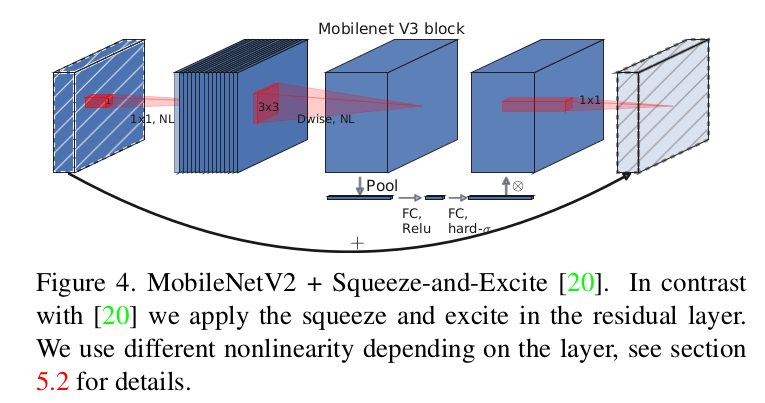
MobileNet V3 网络中还引入了注意力机制,网络结构如下所示。
5.2. 网络实现
h-switch 激活函数实现:
class hswish(nn.Module):
def forward(self, x):
out = x * F.relu6(x + 3, inplace=True) / 6
return out
注意力机制实现如下:
- 首先对输入的特征层进行平均池化,输出大小为 1
- 然后使用 1x1 卷积,先升维再降维
- 最后使用 hsigmoid 将输出固定到 [0,1] 之间
- 再前向传播过程中,将输入乘以注意力机制输出的结果
- 注意力机制相当与让输入的特征乘以一个权重,让网络更关注权重大的特征 ``` class hsigmoid(nn.Module): def forward(self, x): out = F.relu6(x + 3, inplace=True) / 6 return out
class SeModule(nn.Module): def init(self, in_size, reduction=4): super(SeModule, self).init() self.se = nn.Sequential( nn.AdaptiveAvgPool2d(1), nn.Conv2d(in_size, in_size // reduction, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(in_size // reduction), nn.ReLU(inplace=True), nn.Conv2d(in_size // reduction, in_size, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(in_size), hsigmoid() )
def forward(self, x):
return x * self.se(x) ```
定义 MobileNet V3 网络结构。
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, kernel_size, in_size, expand_size, out_size, nolinear, semodule, stride):
super(Block, self).__init__()
self.stride = stride
self.se = semodule
self.conv1 = nn.Conv2d(in_size, expand_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(expand_size)
self.nolinear1 = nolinear
self.conv2 = nn.Conv2d(expand_size, expand_size, kernel_size=kernel_size, stride=stride, padding=kernel_size//2, groups=expand_size, bias=False)
self.bn2 = nn.BatchNorm2d(expand_size)
self.nolinear2 = nolinear
self.conv3 = nn.Conv2d(expand_size, out_size, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_size)
self.shortcut = nn.Sequential()
if stride == 1 and in_size != out_size:
self.shortcut = nn.Sequential(
nn.Conv2d(in_size, out_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_size),
)
def forward(self, x):
out = self.nolinear1(self.bn1(self.conv1(x)))
out = self.nolinear2(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
if self.se != None:
out = self.se(out)
out = out + self.shortcut(x) if self.stride==1 else out
return out
定义 MobileNet V3 small 网络。
class MobileNetV3_Small(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3_Small, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.hs1 = hswish()
self.bneck = nn.Sequential(
Block(3, 16, 16, 16, nn.ReLU(inplace=True), SeModule(16), 2),
Block(3, 16, 72, 24, nn.ReLU(inplace=True), None, 2),
Block(3, 24, 88, 24, nn.ReLU(inplace=True), None, 1),
Block(5, 24, 96, 40, hswish(), SeModule(40), 2),
Block(5, 40, 240, 40, hswish(), SeModule(40), 1),
Block(5, 40, 240, 40, hswish(), SeModule(40), 1),
Block(5, 40, 120, 48, hswish(), SeModule(48), 1),
Block(5, 48, 144, 48, hswish(), SeModule(48), 1),
Block(5, 48, 288, 96, hswish(), SeModule(96), 2),
Block(5, 96, 576, 96, hswish(), SeModule(96), 1),
Block(5, 96, 576, 96, hswish(), SeModule(96), 1),
)
self.conv2 = nn.Conv2d(96, 576, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(576)
self.hs2 = hswish()
self.linear3 = nn.Linear(576, 1280)
self.bn3 = nn.BatchNorm1d(1280)
self.hs3 = hswish()
self.linear4 = nn.Linear(1280, num_classes)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
out = self.hs1(self.bn1(self.conv1(x)))
out = self.bneck(out)
out = self.hs2(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 7)
out = out.view(out.size(0), -1)
out = self.hs3(self.bn3(self.linear3(out)))
out = self.linear4(out)
return out
定义 MobileNet V3 large 网络。
class MobileNetV3_Large(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3_Large, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.hs1 = hswish()
self.bneck = nn.Sequential(
Block(3, 16, 16, 16, nn.ReLU(inplace=True), None, 1),
Block(3, 16, 64, 24, nn.ReLU(inplace=True), None, 2),
Block(3, 24, 72, 24, nn.ReLU(inplace=True), None, 1),
Block(5, 24, 72, 40, nn.ReLU(inplace=True), SeModule(40), 2),
Block(5, 40, 120, 40, nn.ReLU(inplace=True), SeModule(40), 1),
Block(5, 40, 120, 40, nn.ReLU(inplace=True), SeModule(40), 1),
Block(3, 40, 240, 80, hswish(), None, 2),
Block(3, 80, 200, 80, hswish(), None, 1),
Block(3, 80, 184, 80, hswish(), None, 1),
Block(3, 80, 184, 80, hswish(), None, 1),
Block(3, 80, 480, 112, hswish(), SeModule(112), 1),
Block(3, 112, 672, 112, hswish(), SeModule(112), 1),
Block(5, 112, 672, 160, hswish(), SeModule(160), 1),
Block(5, 160, 672, 160, hswish(), SeModule(160), 2),
Block(5, 160, 960, 160, hswish(), SeModule(160), 1),
)
self.conv2 = nn.Conv2d(160, 960, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(960)
self.hs2 = hswish()
self.linear3 = nn.Linear(960, 1280)
self.bn3 = nn.BatchNorm1d(1280)
self.hs3 = hswish()
self.linear4 = nn.Linear(1280, num_classes)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
out = self.hs1(self.bn1(self.conv1(x)))
out = self.bneck(out)
out = self.hs2(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 7)
out = out.view(out.size(0), -1)
out = self.hs3(self.bn3(self.linear3(out)))
out = self.linear4(out)
return out