1. 概述
本篇文章介绍 RPN 网络,相比于 Fast-RCNN 网络, RPN 网络是 Faster-RCNN 最重要的改进之一。使用 RPN 结构生成候选框,将 RPN 生成的候选框投影到特征图上获得相应的特征矩阵。对于特征图上的每个 3x3 的滑动窗口,计算出滑动窗口中心点对应原始图像上的中心点,并计算出 k 个 anchor boxes 。 RPN 网络框架图如下图所示:
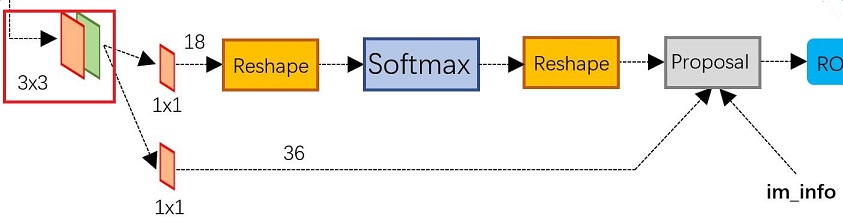
从上图可以看出 RPN 网络分为 2 条线,上面一条通过 softmax 判断 anchors 是 positive 还是 negative 的,下面一条用于计算 anchors 相对于目标的 bounding box regression 偏移量,以获得精确的 proposal 。而最后的 Proposal 层则负责综合 positive anchors 和对应 bounding box regression 偏移量获取proposals ,同时剔除太小和超出边界的 proposals 。
在 FasterRCNN 类中创建 RPN 网络, FasterRCNN 网络初始化参数以及含义如下:
min_size=800, max_size=1000 # 预处理 resize 时限制的最小尺寸与最大尺寸
image_mean=None, image_std=None # 预处理 normalize 时使用的均值和方差,比如初始化的权重训练来自 ImageNet 则这里应该使用 ImageNet 数据集的均值和方差。
# RPN parameters
# rpn 中在 nms 处理前保留的 proposal 数(根据 score)
rpn_pre_nms_top_n_train=2000, rpn_pre_nms_top_n_test=1000
# rpn 中在 nms 处理后保留的 proposal 数
rpn_post_nms_top_n_train=2000, rpn_post_nms_top_n_test=1000
# rpn 中进行 nms 处理时使用的 iou 阈值
rpn_nms_thresh=0.7,
# rpn 计算损失时,采集正负样本设置的阈值
rpn_fg_iou_thresh=0.7, rpn_bg_iou_thresh=0.3,
# rpn 计算损失时采样的样本数,以及正样本占总样本的比例
rpn_batch_size_per_image=256, rpn_positive_fraction=0.5,
# Box parameters
# 移除低目标概率, fast rcnn 中进行 nms 处理的阈值 对预测结果根据 score 排序取前 100 个目标
box_score_thresh=0.05, box_nms_thresh=0.5, box_detections_per_img=100,
# fast rcnn 计算误差时,采集正负样本设置的阈值
box_fg_iou_thresh=0.5, box_bg_iou_thresh=0.5,
# fast rcnn 计算误差时采样的样本数,以及正样本占所有样本的比例
box_batch_size_per_image=512, box_positive_fraction=0.25,
用来生成 Anchors 的代码:
anchor_sizes = ((32,), (64,), (128,), (256,), (512,))
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes)
rpn_anchor_generator = AnchorsGenerator(anchor_sizes, aspect_ratios)
用来生成 RPN 预测网络:
rpn_head = RPNHead(out_channels, rpn_anchor_generator.num_anchors_per_location()[0])
定义整个 RPN 网络:
rpn = RegionProposalNetwork(
rpn_anchor_generator, rpn_head,
rpn_fg_iou_thresh, rpn_bg_iou_thresh,
rpn_batch_size_per_image, rpn_positive_fraction,
rpn_pre_nms_top_n, rpn_post_nms_top_n, rpn_nms_thresh)
2. Anchors
Anchors 就是在特征图上的每一个 3x3 滑动窗口中心点对应原始图像上的中心点,生成 k 个不同大小、不同高宽比的矩形框。
AnchorsGenerator 初始化函数。
- self.sizes: Anchors 的大小, resnet50-fpn 有 5 个预测特征层,每一层生成的 Anchors 的大小分别为: ((32,), (64,), (128,), (256,), (512,))
- self.aspect_ratios: Anchors 的高宽比,为 ((0.5, 1.0, 2.0),)
- self.cell_anchors: 变量用于保存生成的 Anchors 的模板
- self._cache: 变量用于存放一个批量图像的所有预测特征层对应的 Anchors
def __init__(self, sizes=(128, 256, 512), aspect_ratios=(0.5, 1.0, 2.0)): super(AnchorsGenerator, self).__init__() if not isinstance(sizes[0], (list, tuple)): # TODO change this sizes = tuple((s,) for s in sizes) if not isinstance(aspect_ratios[0], (list, tuple)): aspect_ratios = (aspect_ratios,) * len(sizes) assert len(sizes) == len(aspect_ratios) self.sizes = sizes self.aspect_ratios = aspect_ratios self.cell_anchors = None self._cache = {}
AnchorsGenerator 前向传播函数。参数是一个批量的图像数据和批量预测特征图。
- grid_sizes: 保存每一个预测特征图的尺寸
- image_size: 保存图像的尺寸
- strides: 保存原始图像与每一层预测特征图的宽度和高度的比值
- self.set_cell_anchors: 该函数用来生成 Anchors 模板, Anchors 的生成是使用模板在预测特征图上的映射
- self.cached_grid_anchors: 该函数生成每个预测特征层对应的 Anchors ,保存到 anchors_over_all_feature_maps 中。
- anchors: 遍历每一张图片,将所有的 anchors 拼接在一起。
def forward(self, image_list, feature_maps): # type: (ImageList, List[Tensor]) # 获取每个预测特征层的尺寸(height, width) grid_sizes = list([feature_map.shape[-2:] for feature_map in feature_maps]) # 获取输入图像的height和width image_size = image_list.tensors.shape[-2:] # 获取变量类型和设备类型 dtype, device = feature_maps[0].dtype, feature_maps[0].device # one step in feature map equate n pixel stride in origin image # 计算特征层上的一步等于原始图像上的步长 strides = [[torch.tensor(image_size[0] / g[0], dtype=torch.int64, device=device), torch.tensor(image_size[1] / g[1], dtype=torch.int64, device=device)] for g in grid_sizes] # 根据提供的sizes和aspect_ratios生成anchors模板 self.set_cell_anchors(dtype, device) # 计算/读取所有anchors的坐标信息(这里的anchors信息是映射到原图上的所有anchors信息,不是anchors模板) # 得到的是一个list列表,对应每张预测特征图映射回原图的anchors坐标信息 anchors_over_all_feature_maps = self.cached_grid_anchors(grid_sizes, strides) anchors = torch.jit.annotate(List[List[torch.Tensor]], []) # 遍历一个batch中的每张图像 for i, (image_height, image_width) in enumerate(image_list.image_sizes): anchors_in_image = [] # 遍历每张预测特征图映射回原图的anchors坐标信息 for anchors_per_feature_map in anchors_over_all_feature_maps: anchors_in_image.append(anchors_per_feature_map) anchors.append(anchors_in_image) # 将每一张图像的所有预测特征层的anchors坐标信息拼接在一起 # anchors是个list,每个元素为一张图像的所有anchors信息 anchors = [torch.cat(anchors_per_image) for anchors_per_image in anchors] # Clear the cache in case that memory leaks. self._cache.clear() return anchors
如果 self.cell_anchors 不是 None ,则直接返回;否则调用 generate_anchors 去生成 Anchors ,保存到 self.cell_anchors 。
def set_cell_anchors(self, dtype, device):
# type: (int, Device) -> None
if self.cell_anchors is not None:
cell_anchors = self.cell_anchors
assert cell_anchors is not None
# suppose that all anchors have the same device
# which is a valid assumption in the current state of the codebase
if cell_anchors[0].device == device:
return
# 根据提供的sizes和aspect_ratios生成anchors模板
# anchors模板都是以(0, 0)为中心的anchor
cell_anchors = [
self.generate_anchors(sizes, aspect_ratios, dtype, device)
for sizes, aspect_ratios in zip(self.sizes, self.aspect_ratios)
]
self.cell_anchors = cell_anchors
生成 Anchors 模板,模板都是以 (0,0) 坐标为中心。
- h_ratios: aspect_ratios 的平方根,这么做的目的就是为了保证不同高宽比下生成的 Anchors 面积接近。
- w_ratios: 1/h_ratios
- w_ratios[:, None] 和 scales[None, :] 的作用是升维,区别在于前者在最后一个维度上升维,后者是在最前一个维度上升维
- ws = w_ratios*scales
- hs = h_ratios*scales
- view(-1) 的作用是降维,不明白为什么要先升维再降维,直接 w_ratios*scales 也能得到 ws
- base_anchors: 将 [-ws, -hs, ws, hs] 在 dim=1 维度上进行拼接,因为是以 (0,0) 坐标为中心,所以要除以 2
def generate_anchors(self, scales, aspect_ratios, dtype=torch.float32, device="cpu"): # type: (List[int], List[float], int, Device) """ compute anchor sizes Arguments: scales: sqrt(anchor_area) aspect_ratios: h/w ratios dtype: float32 device: cpu/gpu """ scales = torch.as_tensor(scales, dtype=dtype, device=device) aspect_ratios = torch.as_tensor(aspect_ratios, dtype=dtype, device=device) h_ratios = torch.sqrt(aspect_ratios) w_ratios = 1.0 / h_ratios # [r1, r2, r3]' * [s1, s2, s3] # number of elements is len(ratios)*len(scales) ws = (w_ratios[:, None] * scales[None, :]).view(-1) hs = (h_ratios[:, None] * scales[None, :]).view(-1) # left-top, right-bottom coordinate relative to anchor center(0, 0) # 生成的anchors模板都是以(0, 0)为中心的, shape [len(ratios)*len(scales), 4] base_anchors = torch.stack([-ws, -hs, ws, hs], dim=1) / 2 return base_anchors.round() # round 四舍五入
cached_grid_anchors 函数用来生成所有 Anchors ,如果 self._cache 变量中已经存在则直接返回。 否则调用 self.grid_anchors 生成 Anchors ,并更新 self._cache 。
def cached_grid_anchors(self, grid_sizes, strides):
# type: (List[List[int]], List[List[Tensor]])
"""将计算得到的所有anchors信息进行缓存"""
key = str(grid_sizes) + str(strides)
# self._cache是字典类型
if key in self._cache:
return self._cache[key]
anchors = self.grid_anchors(grid_sizes, strides)
self._cache[key] = anchors
return anchors
grid_anchors 函数遍历每一个预测特征层的大小、原图与预测特征层的步距、 Anchors 模板生成所有 Anchors 。生成的 Anchors 是基于原图的,所以首先要将特征图映射到原图, shifts_x 和 shifts_y 保存的是原图尺寸的网格点,间隔为 stride 特征图压缩比例。使用 meshgrid 函数生成坐标矩阵。 坐标矩阵 X 、 Y 每一位置对应的元素可组成一个在原图上的坐标,即 Anchors 的中心点。坐标矩阵有如下特点: X 的每一行都一样, Y 的每一列都一样。
将 shifts_x 和 shifts_y 展平后,使用 stack 组合成坐标点,再加上 Anchors 模板就得到了该特征层对应的所有 Anchors 了。
def grid_anchors(self, grid_sizes, strides):
# type: (List[List[int]], List[List[Tensor]])
"""
anchors position in grid coordinate axis map into origin image
计算预测特征图对应原始图像上的所有anchors的坐标
Args:
grid_sizes: 预测特征矩阵的height和width
strides: 预测特征矩阵上一步对应原始图像上的步距
"""
anchors = []
cell_anchors = self.cell_anchors
assert cell_anchors is not None
# 遍历每个预测特征层的grid_size,strides和cell_anchors
for size, stride, base_anchors in zip(grid_sizes, strides, cell_anchors):
grid_height, grid_width = size
stride_height, stride_width = stride
device = base_anchors.device
# For output anchor, compute [x_center, y_center, x_center, y_center]
# shape: [grid_width] 对应原图上的x坐标(列)
shifts_x = torch.arange(0, grid_width, dtype=torch.float32, device=device) * stride_width
# shape: [grid_height] 对应原图上的y坐标(行)
shifts_y = torch.arange(0, grid_height, dtype=torch.float32, device=device) * stride_height
# 计算预测特征矩阵上每个点对应原图上的坐标(anchors模板的坐标偏移量)
# torch.meshgrid函数分别传入行坐标和列坐标,生成网格行坐标矩阵和网格列坐标矩阵
# shape: [grid_height, grid_width]
shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x)
shift_x = shift_x.reshape(-1)
shift_y = shift_y.reshape(-1)
# 计算anchors坐标(xmin, ymin, xmax, ymax)在原图上的坐标偏移量
# shape: [grid_width*grid_height, 4]
shifts = torch.stack([shift_x, shift_y, shift_x, shift_y], dim=1)
# For every (base anchor, output anchor) pair,
# offset each zero-centered base anchor by the center of the output anchor.
# 将anchors模板与原图上的坐标偏移量相加得到原图上所有anchors的坐标信息(shape不同时会使用广播机制)
shifts_anchor = shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4)
anchors.append(shifts_anchor.reshape(-1, 4))
return anchors # List[Tensor(all_num_anchors, 4)]
计算每个预测特征层上每个滑动窗口的预测目标数。
def num_anchors_per_location(self):
return [len(s) * len(a) for s, a in zip(self.sizes, self.aspect_ratios)]
3. RPNHead
根据 RPN 网络框架图可知,主干网络输出的预测特征层首先经过 3x3 滑动窗口,然后分两条分支,一条分支通过 1x1 卷积,输出维度为 num_anchors(Anchors 大小),用来预测该 Anchors 是否包含物体;另一条分支通过 1x1 卷积,输出维度为 num_anchors*4(每个 Anchors 的预测偏移量) 。
- in_channels: RPNHead 网络的输入通道数,传入值为主干网络输出的通道数
- num_anchors: 每一个像素点 anchor 的个数
def __init__(self, in_channels, num_anchors): super(RPNHead, self).__init__() # 3x3 滑动窗口 self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1) # 计算预测的目标分数(这里的目标只是指前景或者背景) self.cls_logits = nn.Conv2d(in_channels, num_anchors, kernel_size=1, stride=1) # 计算预测的目标bbox regression参数 self.bbox_pred = nn.Conv2d(in_channels, num_anchors * 4, kernel_size=1, stride=1) for layer in self.children(): if isinstance(layer, nn.Conv2d): torch.nn.init.normal_(layer.weight, std=0.01) torch.nn.init.constant_(layer.bias, 0)
前向传播网络用来计算 logits 和 bbox_reg ,并返回给后续网络做处理。
def forward(self, x):
# type: (List[Tensor]) -> Tuple[List[Tensor], List(Tensor)]
logits = []
bbox_reg = []
for i, feature in enumerate(x):
t = F.relu(self.conv(feature))
logits.append(self.cls_logits(t))
bbox_reg.append(self.bbox_pred(t))
return logits, bbox_reg
4. RegionProposalNetwork
RegionProposalNetwork 类定义了整个 RPN 网络框架,其中 init 函数主要作一些初始化操作,将 RPN 网络的各个子模块进行整合到一个类中。
- self.anchor_generator: 用来生成 Anchors
- self.head: 是 RPN 网络中的预测网络部分
- self.box_coder: 用来对预测边界框编解码,包括计算边界框训练标签和根据预测边界框计算候选框
- self.box_similarity: 计算 anchors 与真实 bbox 的 iou
- self.proposal_matcher: 根据阈值选择正负样本,当 iou 大于 fg_iou_thresh(0.7) 时视为正样本,当 iou 小于 bg_iou_thresh(0.3) 时视为负样本
- self.fg_bg_sampler: 按比例选取正负样本,平衡正负样本
- self._pre_nms_top_n: 在 nms 处理前保留的 proposal 数(根据 score)
- self._post_nms_top_n: 在 nms 处理后保留的 proposal 数
- self.nms_thresh: 进行 nms 处理时使用的 iou 阈值
- self.min_size: RPN 网络生成边界框后应用到 anchors 上得到的 boxes 的宽和高都不能小于这个 min_size
class RegionProposalNetwork(torch.nn.Module): __annotations__ = { 'box_coder': det_utils.BoxCoder, 'proposal_matcher': det_utils.Matcher, 'fg_bg_sampler': det_utils.BalancedPositiveNegativeSampler, 'pre_nms_top_n': Dict[str, int], 'post_nms_top_n': Dict[str, int], } def __init__(self, anchor_generator, head, fg_iou_thresh, bg_iou_thresh, batch_size_per_image, positive_fraction, pre_nms_top_n, post_nms_top_n, nms_thresh): super(RegionProposalNetwork, self).__init__() self.anchor_generator = anchor_generator self.head = head self.box_coder = det_utils.BoxCoder(weights=(1.0, 1.0, 1.0, 1.0)) # use during training # 计算anchors与真实bbox的iou self.box_similarity = box_ops.box_iou self.proposal_matcher = det_utils.Matcher( fg_iou_thresh, # 当iou大于fg_iou_thresh(0.7)时视为正样本 bg_iou_thresh, # 当iou小于bg_iou_thresh(0.3)时视为负样本 allow_low_quality_matches=True ) self.fg_bg_sampler = det_utils.BalancedPositiveNegativeSampler( batch_size_per_image, positive_fraction # 256, 0.5 ) # use during testing self._pre_nms_top_n = pre_nms_top_n self._post_nms_top_n = post_nms_top_n self.nms_thresh = nms_thresh self.min_size = 1e-3
RegionProposalNetwork 的前向传播网络,
- 使用 RPN 预测网络预测每个预测特征层每个 Anchors 的类别以及边界框回归参数;
- 对每个预测特征图生成对应原图的 Anchors ;
- 计算每个预测特征层上 Anchors 的个数,每个像素点生成 3 个 Anchors ,每个预测特征图生成的 Anchros 个数为 height x width x 3;
- 使用 concat_box_prediction_layers 函数对 box_cls 和 box_regression 两个 tensor 的排列顺序以及 shape 进行调整,经过 concat_box_prediction_layers 函数后, box_cls 和 box_regression 两个 tensor 的形状为 (-1, 1) 和 (-1, 4) 。
- self.box_coder.decode: 将预测的 pred_bbox_deltas 参数应用到 anchors 上得到最终预测 bbox 坐标,并对该坐标进行 reshape 成 (num_images, -1, 4) 得到 proposals
- self.filter_proposals: 筛除小 boxes 框,进行 nms 处理,根据预测概率获取前 post_nms_top_n 个目标
- 如果是训练模式,self.assign_targets_to_anchors: 计算每个 anchors 最匹配的 gt ,并将 anchors 进行分类,前景,背景以及废弃的 anchors
- self.box_coder.encode: 根据 anchors 的最佳匹配的 gt 和 anchors 计算边界框回归目标
- self.compute_loss: 计算分类损失和边界框回归损失。
- 返回 rpn 网络生成的边界框 box 和损失
def forward(self, images, features, targets=None): # type: (ImageList, Dict[str, Tensor], Optional[List[Dict[str, Tensor]]]) # RPN uses all feature maps that are available # features是所有预测特征层组成的OrderedDict features = list(features.values()) # 计算每个预测特征层上的预测目标概率和bboxes regression参数 # objectness和pred_bbox_deltas都是list objectness, pred_bbox_deltas = self.head(features) # 生成一个batch图像的所有anchors信息,list(tensor)元素个数等于batch_size anchors = self.anchor_generator(images, features) # batch_size num_images = len(anchors) # numel() Returns the total number of elements in the input tensor. # 计算每个预测特征层上的对应的anchors数量 num_anchors_per_level_shape_tensors = [o[0].shape for o in objectness] num_anchors_per_level = [s[0] * s[1] * s[2] for s in num_anchors_per_level_shape_tensors] # 调整内部tensor格式以及shape objectness, pred_bbox_deltas = concat_box_prediction_layers(objectness, pred_bbox_deltas) # apply pred_bbox_deltas to anchors to obtain the decoded proposals # note that we detach the deltas because Faster R-CNN do not backprop through # the proposals # 将预测的bbox regression参数应用到anchors上得到最终预测bbox坐标 proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors) proposals = proposals.view(num_images, -1, 4) # 筛除小boxes框,nms处理,根据预测概率获取前post_nms_top_n个目标 boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level) losses = {} if self.training: assert targets is not None # 计算每个anchors最匹配的gt,并将anchors进行分类,前景,背景以及废弃的anchors labels, matched_gt_boxes = self.assign_targets_to_anchors(anchors, targets) # 结合anchors以及对应的gt,计算regression参数 regression_targets = self.box_coder.encode(matched_gt_boxes, anchors) loss_objectness, loss_rpn_box_reg = self.compute_loss( objectness, pred_bbox_deltas, labels, regression_targets ) losses = { "loss_objectness": loss_objectness, "loss_rpn_box_reg": loss_rpn_box_reg } return boxes, losses
遍历每一个预测特征层的 box_cls 和 box_regression ,将每个预测特征层的类别预测和边界框回归预测值全部收集到一起,并 reshape 成 [N, 1] 和 [N, 4] 的形式。 permute_and_flatten 的作用是调整 tensor 顺序,并进行 reshape 。
这里先疏理一下一个 batch 的数据维度是如何变化的,这里假设 batch_size 的大小是 2 ,那么输入数据的维度为 [2, 3, h, w] ;经过主干特征提取网络后数据的格式变为 [2, 256, f_h, f_w] ,这里需要注意,由于我们使用的是带 FPN 的特征提取网络,所以有多少个特征层就有多少个这样的结构,每个特征层的 f_h 和 f_w 值不同,最后所有层的数据格式存储在链表里;这些特征经过 rpn 网络后,得到的数据格式为 objectness 是 [2, 3, f_h, f_w] , pred_bbox_deltas 是 [2, 12, f_h, f_w] ,其中 objectness 中的 3 表示 3 个 anchor ,由于 rpn 网络只预测前景和背景,所以是 3x1 , pred_bbox_deltas 中的 12 表示 3 个 anchor ,每个 anchor 预测 4 个边界框参数,所以是 3x4 ,这里也是每个特征层的 f_h 和 f_w 值不同,所有层的数据格式存储在链表里;
- 函数最终返回的是一个 batch 中所有 anchor 预测的类别以及边界框回归参数,格式分别为 [N, 1] 和 [N, 4] ,其中 N 为一个 batch 中所有的 anchor 数。
-
flatten(0, -2): 展平,起始维度是 0 ,结束维度是 -2 ``` def concat_box_prediction_layers(box_cls, box_regression): # type: (List[Tensor], List[Tensor])
box_cls_flattened = [] box_regression_flattened = []
# 遍历每个预测特征层 for box_cls_per_level, box_regression_per_level in zip(box_cls, box_regression): # [batch_size, anchors_num_per_position * classes_num, height, width] # 注意,当计算RPN中的proposal时,classes_num=1,只区分目标和背景 N, AxC, H, W = box_cls_per_level.shape # # [batch_size, anchors_num_per_position * 4, height, width] Ax4 = box_regression_per_level.shape[1] # anchors_num_per_position A = Ax4 // 4 # classes_num C = AxC // A
# [N, -1, C] box_cls_per_level = permute_and_flatten(box_cls_per_level, N, A, C, H, W) box_cls_flattened.append(box_cls_per_level) # [N, -1, C] box_regression_per_level = permute_and_flatten(box_regression_per_level, N, A, 4, H, W) box_regression_flattened.append(box_regression_per_level)box_cls = torch.cat(box_cls_flattened, dim=1).flatten(0, -2) # start_dim, end_dim box_regression = torch.cat(box_regression_flattened, dim=1).reshape(-1, 4) return box_cls, box_regression
def permute_and_flatten(layer, N, A, C, H, W): # type: (Tensor, int, int, int, int, int)
# view和reshape功能是一样的,先展平所有元素在按照给定shape排列
# view函数只能用于内存中连续存储的tensor,permute等操作会使tensor在内存中变得不再连续,此时就不能再调用view函数
# reshape则不需要依赖目标tensor是否在内存中是连续的
# [batch_size, anchors_num_per_position * (C or 4), height, width]
layer = layer.view(N, -1, C, H, W)
# 调换tensor维度
layer = layer.permute(0, 3, 4, 1, 2) # [N, H, W, -1, C]
layer = layer.reshape(N, -1, C)
return layer ```
filter_proposals 函数用来筛选预选框。函数输入 proposals 形状为 [num_images, -1, 4] , objectness 形状为 [N, 1] 。
- objectness: 对 objectness 进行 reshape 到 (num_images, -1)
- levels 负责记录选中的预测值在哪个层上,torch.full((n,), idx) 用来生成一个 (n,) 维的张量,每个值都为 idx
- 将 levels reshape 到 (-1, 1) 并 扩展到与 objectness 相同的形状。
- self._get_top_n_idx: 获取每个 batch 上预测概率排前 pre_nms_top_n 的 anchors 索引值,返回的数据形状为 [2, n] 。每一个预测特征层选取最多 2000 个预测值。
- image_range = torch.arange(num_images, device=device): 根据 batch_size 生成 image_range
- batch_idx = image_range[:, None]: 对 image_range 升维得到 batch_idx ,用于二维数组的索引定位
- objectness = objectness[batch_idx, top_n_idx]: 根据索引获取每一张图片的类别信息。
- levels = levels[batch_idx, top_n_idx]: 根据索引获取每一个预测特征图的分割信息。
- proposals = proposals[batch_idx, top_n_idx]: 根据索引获取每一张图片的边界框回归信息。
- box_ops.clip_boxes_to_image: 遍历每一张图片,调整预测的 boxes 信息,将越界的坐标调整到图片边界上,限制 x 坐标范围在 [0,width] 之间;限制 y 坐标范围在 [0,height] 之间
- box_ops.remove_small_boxes: 移除宽高小于指定阈值的索引
- boxes[keep], scores[keep], lvl[keep]: 筛选出满足条件的数据
- box_ops.batched_nms: 对每一张图像的每一个预测特征层的边界框进行极大值抑制
- keep[: self.post_nms_top_n()]: 获取每一张图片前 post_nms_top_n 个预选框和类别分数
- 函数最终返回筛选过的预测类别和边界框,形状分别为 [2000, 1] 和 [2000, 4] ,这是一张图片的返回数据,一个 batch 的图像添加到链表里返回。
def filter_proposals(self, proposals, objectness, image_shapes, num_anchors_per_level): # type: (Tensor, Tensor, List[Tuple[int, int]], List[int]) num_images = proposals.shape[0] device = proposals.device # do not backprop throught objectness objectness = objectness.detach() objectness = objectness.reshape(num_images, -1) # Returns a tensor of size size filled with fill_value # levels负责记录分隔不同预测特征层上的anchors索引信息 levels = [torch.full((n, ), idx, dtype=torch.int64, device=device) for idx, n in enumerate(num_anchors_per_level)] levels = torch.cat(levels, 0) # Expand this tensor to the same size as objectness levels = levels.reshape(1, -1).expand_as(objectness) # select top_n boxes independently per level before applying nms # 获取每张预测特征图上预测概率排前pre_nms_top_n的anchors索引值 top_n_idx = self._get_top_n_idx(objectness, num_anchors_per_level) image_range = torch.arange(num_images, device=device) batch_idx = image_range[:, None] # [batch_size, 1] # 根据每个预测特征层预测概率排前pre_nms_top_n的anchors索引值获取相应概率信息 objectness = objectness[batch_idx, top_n_idx] levels = levels[batch_idx, top_n_idx] # 预测概率排前pre_nms_top_n的anchors索引值获取相应bbox坐标信息 proposals = proposals[batch_idx, top_n_idx] final_boxes = [] final_scores = [] # 遍历每张图像的相关预测信息 for boxes, scores, lvl, img_shape in zip(proposals, objectness, levels, image_shapes): # 调整预测的boxes信息,将越界的坐标调整到图片边界上 boxes = box_ops.clip_boxes_to_image(boxes, img_shape) # 返回boxes满足宽,高都大于min_size的索引 keep = box_ops.remove_small_boxes(boxes, self.min_size) boxes, scores, lvl = boxes[keep], scores[keep], lvl[keep] # non-maximum suppression, independently done per level keep = box_ops.batched_nms(boxes, scores, lvl, self.nms_thresh) # keep only topk scoring predictions keep = keep[: self.post_nms_top_n()] boxes, scores = boxes[keep], scores[keep] final_boxes.append(boxes) final_scores.append(scores) return final_boxes, final_scores
获取每张预测特征图上预测概率排前 pre_nms_top_n 的 anchors 索引值。
- 输入 objectness 的形状为: [batchsize, N] , N 为每张图像中所有的 anchor 数。
- objectness.split(num_anchors_per_level, 1): 在维度 1 上将 objectness 按每个预测特征图的 anchors 数划分。
- pre_nms_top_n: nms 处理前保留的 proposals 个数
- ob.topk(pre_nms_top_n, dim=1): 选取当前预测特征层,前 pre_nms_top_n 个 objectness 的索引。注意,这里返回的形状为 [2, 2000] ,因为 ob 是二维的,且这里设置的 dim=1 。
- torch.cat(r, dim=1): 将每一层所选取的 objectness 的索引拼接到一起。最终返回的维度是 [2, 8578]
def _get_top_n_idx(self, objectness, num_anchors_per_level): # type: (Tensor, List[int]) r = [] # 记录每个预测特征层上预测目标概率前pre_nms_top_n的索引信息 offset = 0 # 遍历每个预测特征层上的预测目标概率信息 for ob in objectness.split(num_anchors_per_level, 1): if torchvision._is_tracing(): num_anchors, pre_nms_top_n = _onnx_get_num_anchors_and_pre_nms_top_n(ob, self.pre_nms_top_n()) else: num_anchors = ob.shape[1] # 预测特征层上的预测的anchors个数 pre_nms_top_n = min(self.pre_nms_top_n(), num_anchors) # self.pre_nms_top_n=1000 # Returns the k largest elements of the given input tensor along a given dimension _, top_n_idx = ob.topk(pre_nms_top_n, dim=1) r.append(top_n_idx + offset) offset += num_anchors return torch.cat(r, dim=1)
assign_targets_to_anchors 函数计算每个 anchors 最匹配的 gt ,并划分为正样本,背景以及废弃的样本。正负样本选取规则是 anchor 与 gt 的 iou 大与 0.7 作为正样本,小于 0.3 作为负样本,在 [0.3, 0.7] 之间的丢弃;对于与 gt box 有最大 iou 的 anchor 也设为正样本,即使该 iou 小于 0.3 。
- 传入参数分别是一个批量数据的所有 anchors (维度为 [N, 4])和标注信息(字典结构)。每一个 batch 的图片的信息以列表形式存储。
- 遍历一个批量数据中的每一张图片,分别取出每一张图片对应的 anchors 和标注信息。
- gt_boxes: 保存的是真实物体的边界框信息。
- box_ops.box_iou: 计算图片中的真实 bbox 与每一个 anchors 的 iou 。返回值的形状为 [n, A] ,其中 n 为这张图片 gt 的个数, A 为这张图片总共生成的 anchor 大小。
- self.proposal_matcher: 计算每个 anchors 与 gt 匹配 iou 最大值对应的索引,iou 小于 low_threshold 的索引置为 -1 , iou 在 [low_threshold, high_threshold] 之间的索引置为 -2 ;计算每个 gt boxes 与其 iou 最大的 anchor ,保留该 anchor 匹配 gt 最大 iou 的索引,即使 iou 低于设定的阈值。
- matched_gt_boxes_per_image: 保存每一个 Anchors 对应的 gt boxes ,将那些负样本和不参与训练的样本的 Anchors 的 gt boxes 默认设为了 gt_boxes[0] ,在计算损失时会根据 labels_per_image 值进行区分正负样本和丢弃样本。
- labels_per_image: 该变量设置每一个 Anchors 的标签。将 matched_idxs >= 0 的,也就是正样本的索引,设置为 True
- bg_indices: 是背景的索引,设置为 True
- labels_per_image[bg_indices]: 将 bg_indices 对应为 True 设置为 0 ,表示负样本
- inds_to_discard: 不参与训练的索引,设置为 True
- labels_per_image[inds_to_discard]: 将 inds_to_discard 对应为 True 设置为 -1 ,表示该样本不参与训练
- 函数返回两个值,一个是 Anchors 是正样本还是负样本的标签,以及样本对应的 gt boxes 边界框。返回的是一个列表,列表中的每一项代表一张图像的数据。
def assign_targets_to_anchors(self, anchors, targets): # type: (List[Tensor], List[Dict[str, Tensor]]) labels = [] matched_gt_boxes = [] for anchors_per_image, targets_per_image in zip(anchors, targets): gt_boxes = targets_per_image["boxes"] if gt_boxes.numel() == 0: device = anchors_per_image.device matched_gt_boxes_per_image = torch.zeros(anchors_per_image.shape, dtype=torch.float32, device=device) labels_per_image = torch.zeros((anchors_per_image.shape[0],), dtype=torch.float32, device=device) else: # 计算anchors与真实bbox的iou信息 # set to self.box_similarity when https://github.com/pytorch/pytorch/issues/27495 lands match_quality_matrix = box_ops.box_iou(gt_boxes, anchors_per_image) # 计算每个anchors与gt匹配iou最大的索引(如果iou<0.3索引置为-1,0.3<iou<0.7索引为-2) matched_idxs = self.proposal_matcher(match_quality_matrix) # get the targets corresponding GT for each proposal # NB: need to clamp the indices because we can have a single # GT in the image, and matched_idxs can be -2, which goes # out of bounds matched_gt_boxes_per_image = gt_boxes[matched_idxs.clamp(min=0)] labels_per_image = matched_idxs >= 0 labels_per_image = labels_per_image.to(dtype=torch.float32) # background (negative examples) bg_indices = matched_idxs == self.proposal_matcher.BELOW_LOW_THRESHOLD # -1 labels_per_image[bg_indices] = torch.tensor(0.0) # discard indices that are between thresholds inds_to_discard = matched_idxs == self.proposal_matcher.BETWEEN_THRESHOLDS # -2 labels_per_image[inds_to_discard] = torch.tensor(-1.0) labels.append(labels_per_image) matched_gt_boxes.append(matched_gt_boxes_per_image) return labels, matched_gt_boxes
计算 RPN 损失,包括类别损失(前景与背景), bbox regression 损失。
- self.fg_bg_sampler: 平衡正负样本,选取 256 个样本,正样本比例为 50% 。遍历每张图像的 matched_idxs ,如果正样本不够就采用所有正样本,如果负样本不够直接采用所有负样本。随机选择指定数量的正负样本 。 sampled_pos_inds 和 sampled_neg_inds 最终存储的是每一个 batch 中的所有正负样本分别拼接到一起。
- sampled_inds: 将所有正负样本拼接到一起,保存的是一个 batch 中所有正负样本的索引。
- objectness, labels, regression_targets: 分别保存了一个 batch 中所有的预测类别、类别标签和边界框回归标签。
- smooth_l1_loss: 计算边界框回归损失
- binary_cross_entropy_with_logits: 计算目标预测概率损失
- 函数返回 objectness_loss, box_loss ,分别是预测类别损失和边界框回归损失。
def compute_loss(self, objectness, pred_bbox_deltas, labels, regression_targets): # type: (Tensor, Tensor, List[Tensor], List[Tensor]) # 按照给定的batch_size_per_image, positive_fraction选择正负样本 sampled_pos_inds, sampled_neg_inds = self.fg_bg_sampler(labels) # 将一个batch中的所有正负样本List(Tensor)分别拼接在一起,并获取非零位置的索引 sampled_pos_inds = torch.nonzero(torch.cat(sampled_pos_inds, dim=0)).squeeze(1) sampled_neg_inds = torch.nonzero(torch.cat(sampled_neg_inds, dim=0)).squeeze(1) # 将所有正负样本索引拼接在一起 sampled_inds = torch.cat([sampled_pos_inds, sampled_neg_inds], dim=0) objectness = objectness.flatten() labels = torch.cat(labels, dim=0) regression_targets = torch.cat(regression_targets, dim=0) # 计算边界框回归损失 box_loss = det_utils.smooth_l1_loss( pred_bbox_deltas[sampled_pos_inds], regression_targets[sampled_pos_inds], beta=1 / 9, size_average=False, ) / (sampled_inds.numel()) # 计算目标预测概率损失 objectness_loss = F.binary_cross_entropy_with_logits( objectness[sampled_inds], labels[sampled_inds] ) return objectness_loss, box_loss
5. 工具类
下面介绍下 boxes 文件里的几个工具函数。
clip_boxes_to_image 函数对每一张图片,调整预测的 boxes 信息,将越界的坐标调整到图片边界上,限制 x 坐标范围在 [0,width] 之间;限制 y 坐标范围在 [0,height] 之间
- boxes 的维度是 [N, 4] , N 是每一张图像生成的候选框的个数
- boxes[…, 0::2]: 第一维是 […] 表示取所有的行,第二维表示从 0 开始,步距是 2 ,这样就取到了 x1 和 x2
- boxes_x.clamp(min=0, max=width): 把 x1 和 x2 限制在 [0-width]
- 最后两句代码是将 boxes_x 和 boxes_y 恢复到原来的维度
def clip_boxes_to_image(boxes, size): # type: (Tensor, Tuple[int, int]) dim = boxes.dim() boxes_x = boxes[..., 0::2] # x1, x2 boxes_y = boxes[..., 1::2] # y1, y2 height, width = size if torchvision._is_tracing(): boxes_x = torch.max(boxes_x, torch.tensor(0, dtype=boxes.dtype, device=boxes.device)) boxes_x = torch.min(boxes_x, torch.tensor(width, dtype=boxes.dtype, device=boxes.device)) boxes_y = torch.max(boxes_y, torch.tensor(0, dtype=boxes.dtype, device=boxes.device)) boxes_y = torch.min(boxes_y, torch.tensor(height, dtype=boxes.dtype, device=boxes.device)) else: boxes_x = boxes_x.clamp(min=0, max=width) # 限制x坐标范围在[0,width]之间 boxes_y = boxes_y.clamp(min=0, max=height) # 限制y坐标范围在[0,height]之间 clipped_boxes = torch.stack((boxes_x, boxes_y), dim=dim) return clipped_boxes.reshape(boxes.shape)
remove_small_boxes 函数移除宽高小于指定阈值的索引。
- ws,hs: 获得预测边界框的宽高
- 获取宽高是否大于 min_size 的布尔数组
- nonzero 函数用于得到 tensor 中非零元素的位置,
def remove_small_boxes(boxes, min_size): # type: (Tensor, float) """ Remove boxes which contains at least one side smaller than min_size. 移除宽高小于指定阈值的索引 Arguments: boxes (Tensor[N, 4]): boxes in (x1, y1, x2, y2) format min_size (float): minimum size Returns: keep (Tensor[K]): indices of the boxes that have both sides larger than min_size """ ws, hs = boxes[:, 2] - boxes[:, 0], boxes[:, 3] - boxes[:, 1] # 预测boxes的宽和高 keep = (ws >= min_size) & (hs >= min_size) # 当满足宽,高都大于给定阈值时为True # nonzero(): Returns a tensor containing the indices of all non-zero elements of input keep = keep.nonzero().squeeze(1) return keep
batched_nms 函数对每一张图像的每一个预测特征层的边界框进行极大值抑制。
- boxes.max() 获取所有 boxes 中最大的坐标值
- offsets: 为每一个类别生成一个很大的偏移量, 这里的 to 只是让生成 tensor 的 dytpe 和 device 与 boxes 保持一致。
- boxes_for_nms: boxes 加上对应层的偏移量后,保证不同类别之间 boxes 不会有重合的现象
- nms: 极大值抑制
def batched_nms(boxes, scores, idxs, iou_threshold): # type: (Tensor, Tensor, Tensor, float) if boxes.numel() == 0: return torch.empty((0,), dtype=torch.int64, device=boxes.device) # strategy: in order to perform NMS independently per class. # we add an offset to all the boxes. The offset is dependent # only on the class idx, and is large enough so that boxes # from different classes do not overlap # 获取所有boxes中最大的坐标值(xmin, ymin, xmax, ymax) max_coordinate = boxes.max() # to(): Performs Tensor dtype and/or device conversion # 为每一个类别生成一个很大的偏移量 # 这里的to只是让生成tensor的dytpe和device与boxes保持一致 offsets = idxs.to(boxes) * (max_coordinate + 1) # boxes加上对应层的偏移量后,保证不同类别之间boxes不会有重合的现象 boxes_for_nms = boxes + offsets[:, None] keep = nms(boxes_for_nms, scores, iou_threshold) return keep
box_iou 函数用来计算两个边界框的交并比。 iou = 边界框的交集 / 边界框的并集。边界框框的交集 = 左上角较大点的坐标与右下角较小点的左边之间的面积;边界框的并集 = 两个边界框的面积和 - 边界框的交集。
def box_iou(boxes1, boxes2):
area1 = box_area(boxes1)
area2 = box_area(boxes2)
# When the shapes do not match,
# the shape of the returned output tensor follows the broadcasting rules
lt = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # left-top [N,M,2]
rb = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # right-bottom [N,M,2]
wh = (rb - lt).clamp(min=0) # [N,M,2]
inter = wh[:, :, 0] * wh[:, :, 1] # [N,M]
iou = inter / (area1[:, None] + area2 - inter)
return iou
下面介绍 det_utils 文件里的函数。
BalancedPositiveNegativeSampler 类,用来平衡正负样本, init 函数初始化每张图片保留的正负样本总数和正样本所占的比例。
def __init__(self, batch_size_per_image, positive_fraction):
# type: (int, float)
self.batch_size_per_image = batch_size_per_image
self.positive_fraction = positive_fraction
call 函数在匹配的正负样本集合中选出所需的正负样本,返回正样本和负样本对应的 mask ,表示选中的位置值为 1 。满足的如下条件:
- 选择的正负样本数不得超过 self.batch_size_per_image
- 选择正样本的比例为 self.positive_fraction
- 如果正样本数量不够就直接采用所有正样本
- 如果负样本数量不够就直接采用所有负样本
def __call__(self, matched_idxs): # type: (List[Tensor]) pos_idx = [] neg_idx = [] # 遍历每张图像的matched_idxs for matched_idxs_per_image in matched_idxs: # >= 1的为正样本, nonzero返回非零元素索引 positive = torch.nonzero(matched_idxs_per_image >= 1).squeeze(1) # = 0的为负样本 negative = torch.nonzero(matched_idxs_per_image == 0).squeeze(1) # 指定正样本的数量 num_pos = int(self.batch_size_per_image * self.positive_fraction) # protect against not enough positive examples # 如果正样本数量不够就直接采用所有正样本 num_pos = min(positive.numel(), num_pos) # 指定负样本数量 num_neg = self.batch_size_per_image - num_pos # protect against not enough negative examples # 如果负样本数量不够就直接采用所有负样本 num_neg = min(negative.numel(), num_neg) # randomly select positive and negative examples # Returns a random permutation of integers from 0 to n - 1. # 随机选择指定数量的正负样本 perm1 = torch.randperm(positive.numel(), device=positive.device)[:num_pos] perm2 = torch.randperm(negative.numel(), device=negative.device)[:num_neg] pos_idx_per_image = positive[perm1] neg_idx_per_image = negative[perm2] # create binary mask from indices pos_idx_per_image_mask = zeros_like( matched_idxs_per_image, dtype=torch.uint8 ) neg_idx_per_image_mask = zeros_like( matched_idxs_per_image, dtype=torch.uint8 ) pos_idx_per_image_mask[pos_idx_per_image] = torch.tensor(1, dtype=torch.uint8) neg_idx_per_image_mask[neg_idx_per_image] = torch.tensor(1, dtype=torch.uint8) pos_idx.append(pos_idx_per_image_mask) neg_idx.append(neg_idx_per_image_mask) return pos_idx, neg_idx
下面介绍 BoxCoder 类,该类用来计算边界框回归参数。
init 函数初始化 self.weights 和 self.bbox_xform_clip 属性, self.weights 用来设置边界框回归参数的权重,默认是 1 ; self.bbox_xform_clip 用来限制 dw 和 dh 的最大值,防止 torch.exp() 值太大。
def __init__(self, weights, bbox_xform_clip=math.log(1000. / 16)):
# type: (Tuple[float, float, float, float], float)
self.weights = weights
self.bbox_xform_clip = bbox_xform_clip
encode 函数用来计算训练回归参数的标签。
- boxes_per_image: 计算每张图片有多少个正负样本 ,后面用来将标签按照每张图片进行分隔
- 首先将 reference_boxes 和 proposals 两个张量在维度 0 上进行拼接
- 调用 encode_single 函数计算 reference_boxes 和 proposals 之间的边界框回归参数,作为训练标签
def encode(self, reference_boxes, proposals): # type: (List[Tensor], List[Tensor]) """ # 统计每张图像的正负样本数,方便后面拼接在一起处理后在分开 # reference_boxes和proposal数据结构相同 boxes_per_image = [len(b) for b in reference_boxes] reference_boxes = torch.cat(reference_boxes, dim=0) proposals = torch.cat(proposals, dim=0) # targets_dx, targets_dy, targets_dw, targets_dh targets = self.encode_single(reference_boxes, proposals) return targets.split(boxes_per_image, 0)
调用 encode_boxes 函数计算边界框回归参数。
def encode_single(self, reference_boxes, proposals):
dtype = reference_boxes.dtype
device = reference_boxes.device
weights = torch.as_tensor(self.weights, dtype=dtype, device=device)
targets = encode_boxes(reference_boxes, proposals, weights)
return targets
边界框回归涉及到两个方面的训练,中心点坐标和宽高的比例。中心点坐标使用平移的方式即可得到;宽高通过尺度的缩放得到。
公式一:边界框回归参数分别为 dx , dy , dw , dh ,这四个参数是网络最终输出的边界框的值, Px , Py , Pw , Ph 分别为候选框的中心坐标以及宽高。 G^x , G^y , G^w , G^h 分别为最终预测的边界框中心坐标以及宽高。得到如下公式:
- G^x = Pw * dx(P)+Px
- G^y = Ph * dy(P)+Py
- G^w = Pw * exp(dw(P))
- G^h = Ph * exp(dh(P))
公式二:根据下面公式即可计算得到边界框回归参数如下:
- tx = (Gx−Px)/Pw
- ty = (Gy−Py)/Ph
- tw = log(Gw/Pw)
- th = log(Gh/Ph)
encode_boxes 函数实现了公式二,计算边界框回归参数的标签值。
def encode_boxes(reference_boxes, proposals, weights):
# type: (torch.Tensor, torch.Tensor, torch.Tensor) -> torch.Tensor
# perform some unpacking to make it JIT-fusion friendly
wx = weights[0]
wy = weights[1]
ww = weights[2]
wh = weights[3]
# unsqueeze()
# Returns a new tensor with a dimension of size one inserted at the specified position.
proposals_x1 = proposals[:, 0].unsqueeze(1)
proposals_y1 = proposals[:, 1].unsqueeze(1)
proposals_x2 = proposals[:, 2].unsqueeze(1)
proposals_y2 = proposals[:, 3].unsqueeze(1)
reference_boxes_x1 = reference_boxes[:, 0].unsqueeze(1)
reference_boxes_y1 = reference_boxes[:, 1].unsqueeze(1)
reference_boxes_x2 = reference_boxes[:, 2].unsqueeze(1)
reference_boxes_y2 = reference_boxes[:, 3].unsqueeze(1)
# implementation starts here
# parse widths and heights
ex_widths = proposals_x2 - proposals_x1
ex_heights = proposals_y2 - proposals_y1
# parse coordinate of center point
ex_ctr_x = proposals_x1 + 0.5 * ex_widths
ex_ctr_y = proposals_y1 + 0.5 * ex_heights
gt_widths = reference_boxes_x2 - reference_boxes_x1
gt_heights = reference_boxes_y2 - reference_boxes_y1
gt_ctr_x = reference_boxes_x1 + 0.5 * gt_widths
gt_ctr_y = reference_boxes_y1 + 0.5 * gt_heights
targets_dx = wx * (gt_ctr_x - ex_ctr_x) / ex_widths
targets_dy = wy * (gt_ctr_y - ex_ctr_y) / ex_heights
targets_dw = ww * torch.log(gt_widths / ex_widths)
targets_dh = wh * torch.log(gt_heights / ex_heights)
targets = torch.cat((targets_dx, targets_dy, targets_dw, targets_dh), dim=1)
return targets
decode 函数根据网络输出的边界框回归参数得到边界框的中心点坐标和宽高。
def decode(self, rel_codes, boxes):
# type: (Tensor, List[Tensor])
"""
assert isinstance(boxes, (list, tuple))
# if isinstance(rel_codes, (list, tuple)):
# rel_codes = torch.cat(rel_codes, dim=0)
assert isinstance(rel_codes, torch.Tensor)
boxes_per_image = [b.size(0) for b in boxes]
concat_boxes = torch.cat(boxes, dim=0)
box_sum = 0
for val in boxes_per_image:
box_sum += val
# 将预测的bbox回归参数应用到对应anchors上得到预测bbox的坐标
pred_boxes = self.decode_single(
rel_codes.reshape(box_sum, -1), concat_boxes
)
return pred_boxes.reshape(box_sum, -1, 4)
调用 decode_single 计算边界框的中心点坐标和宽高,计算公式如上公式一。
def decode_single(self, rel_codes, boxes):
boxes = boxes.to(rel_codes.dtype)
# xmin, ymin, xmax, ymax
widths = boxes[:, 2] - boxes[:, 0] # anchor宽度
heights = boxes[:, 3] - boxes[:, 1] # anchor高度
ctr_x = boxes[:, 0] + 0.5 * widths # anchor中心x坐标
ctr_y = boxes[:, 1] + 0.5 * heights # anchor中心y坐标
wx, wy, ww, wh = self.weights # 默认都是1
dx = rel_codes[:, 0::4] / wx # 预测anchors的中心坐标x回归参数
dy = rel_codes[:, 1::4] / wy # 预测anchors的中心坐标y回归参数
dw = rel_codes[:, 2::4] / ww # 预测anchors的宽度回归参数
dh = rel_codes[:, 3::4] / wh # 预测anchors的高度回归参数
# limit max value, prevent sending too large values into torch.exp()
# self.bbox_xform_clip=math.log(1000. / 16)
dw = torch.clamp(dw, max=self.bbox_xform_clip)
dh = torch.clamp(dh, max=self.bbox_xform_clip)
pred_ctr_x = dx * widths[:, None] + ctr_x[:, None]
pred_ctr_y = dy * heights[:, None] + ctr_y[:, None]
pred_w = torch.exp(dw) * widths[:, None]
pred_h = torch.exp(dh) * heights[:, None]
# xmin
pred_boxes1 = pred_ctr_x - torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_w
# ymin
pred_boxes2 = pred_ctr_y - torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_h
# xmax
pred_boxes3 = pred_ctr_x + torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_w
# ymax
pred_boxes4 = pred_ctr_y + torch.tensor(0.5, dtype=pred_ctr_x.dtype, device=pred_w.device) * pred_h
pred_boxes = torch.stack((pred_boxes1, pred_boxes2, pred_boxes3, pred_boxes4), dim=2).flatten(1)
return pred_boxes
下面介绍 Matcher 类,该类主要用来划分正负样本。
init 函数主要初始化一些属性。
def __init__(self, high_threshold, low_threshold, allow_low_quality_matches=False):
# type: (float, float, bool)
self.BELOW_LOW_THRESHOLD = -1
self.BETWEEN_THRESHOLDS = -2
assert low_threshold <= high_threshold
self.high_threshold = high_threshold
self.low_threshold = low_threshold
self.allow_low_quality_matches = allow_low_quality_matches
call 函数对所有 Anchors 划分正负样本和丢弃样本。
- 计算每一个 Anchors 对应的最大 IOU 的 gt box ,将 IOU 最大值和 anchors 的索引保存到 matched_vals 和 matches 两个变量中。
- allow_low_quality_matches: 是否允许与 gt 有最大 iou 的 anchor 作为正样本,即使 iou 小与 0.3 。默认是 True ,因此以上可能漏掉了某些 gt box ,所以先将 matches 克隆一份,保存到 all_matches 中,进行后续处理
- 将 IOU < self.low_threshold 的 Anchors 的索引值设为 -1
- 将 IOU >= self.low_threshold 并且 IOU < self.high_threshold 的 Anchors 的索引值设为 -2
- 调用 self.set_low_quality_matches_ 函数,计算 gt box 对应 IOU 最大的 Anchors 。
def __call__(self, match_quality_matrix): # match_quality_matrix is M (gt) x N (predicted) # Max over gt elements (dim 0) to find best gt candidate for each prediction # M x N 的每一列代表一个anchors与所有gt的匹配iou值 # matched_vals代表每列的最大值,即每个anchors与所有gt匹配的最大iou值 # matches对应最大值所在的索引 matched_vals, matches = match_quality_matrix.max(dim=0) # the dimension to reduce. if self.allow_low_quality_matches: all_matches = matches.clone() else: all_matches = None # Assign candidate matches with low quality to negative (unassigned) values # 计算iou小于low_threshold的索引 below_low_threshold = matched_vals < self.low_threshold # 计算iou在low_threshold与high_threshold之间的索引值 between_thresholds = (matched_vals >= self.low_threshold) & ( matched_vals < self.high_threshold ) # iou小于low_threshold的matches索引置为-1 matches[below_low_threshold] = torch.tensor(self.BELOW_LOW_THRESHOLD) # -1 # iou在[low_threshold, high_threshold]之间的matches索引置为-2 matches[between_thresholds] = torch.tensor(self.BETWEEN_THRESHOLDS) # -2 if self.allow_low_quality_matches: assert all_matches is not None self.set_low_quality_matches_(matches, all_matches, match_quality_matrix) return matches
set_low_quality_matches_ 函数,计算每个 gt boxes 与其 iou 最大的 anchor 。
- 将最大 IOU 值保存到 highest_quality_foreach_gt 中
- 寻找每个 gt box 与其 iou 最大的 anchors 的索引,一个 gt 匹配到最大 iou 可能有多个 anchors
- 将这些 gt 匹配到最大 iou 的 anchors 的索引重新记录到 matches 中。
- torch.eq: 找到 match_quality_matrix 中 与 gt 有最大的 iou 的 anchor ,得到一个布尔矩阵
- torch.where: 找到布尔矩阵中为 True 的索引,返回 tuple 类型,第一个元素是行的位置,第二个元素是列的位置
- 因为这里要找到作为正样本的 anchor ,所以只需要取第二个维度的元素即可。
def set_low_quality_matches_(self, matches, all_matches, match_quality_matrix): # For each gt, find the prediction with which it has highest quality # 对于每个gt boxes寻找与其iou最大的anchor, # highest_quality_foreach_gt为匹配到的最大iou值 highest_quality_foreach_gt, _ = match_quality_matrix.max(dim=1) # the dimension to reduce. # Find highest quality match available, even if it is low, including ties gt_pred_pairs_of_highest_quality = torch.where( torch.eq(match_quality_matrix, highest_quality_foreach_gt[:, None]) ) pre_inds_to_update = gt_pred_pairs_of_highest_quality[1] # 保留该anchor匹配gt最大iou的索引,即使iou低于设定的阈值 matches[pre_inds_to_update] = all_matches[pre_inds_to_update]
4. 损失函数
RPN 网络损失函数有两个,一个是类别损失,另一个是边界框回归损失。
对于类别损失 pytorch 官方的实现是使用二值交叉熵损失而不是使用论文中描述的多分类交叉熵损失,这也是为什么 RPNHeader 中预测分类目标分数的卷积层 self.cls_logits 输出是 num_anchors 而不是 2*num_anchors 的原因。
对于边界回归损失使用 smooth_l1 损失。 smooth_l1 损失可以从两个方面限制梯度,当预测框与 ground truth 差别过大时,梯度值不至于过大;当预测框与 ground truth 差别很小时,梯度值足够小。相比于 L1 损失函数,可以收敛得更快。相比于 L2 损失函数,对离群点、异常值不敏感,梯度变化相对更小,训练时不容易跑飞。 smooth_l1 函数公式如下图所示:
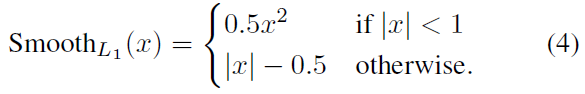
smooth_l1 函数带 sigma 版本公式如下图所示,我看下面这个图好像两个条件写反了。
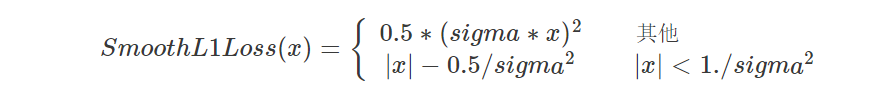
smooth_l1_loss 代码实现如下所示,参数 beta 是 sigma 的变体, beta 值为 1/9 则 sigma 值为 3 。
def smooth_l1_loss(input, target, beta: float = 1. / 9, size_average: bool = True):
"""
very similar to the smooth_l1_loss from pytorch, but with
the extra beta parameter
"""
n = torch.abs(input - target)
cond = n < beta
loss = torch.where(cond, 0.5 * n ** 2 / beta, n - 0.5 * beta)
if size_average:
return loss.mean()
return loss.sum()
RPN 网络就先写道这里了,网络结构还是清晰明了的,就是这过程中张量的变换太烧脑。