1. 概述
这篇文章我们介绍一下在 pytorch 官方提供的 Faster-RCNN 源码实现中使用的 backbone —— resnet50_fpn 。
2. FPN 网络介绍
FPN 是 Feature Pyramid Networks 的简称,意为特征金字塔。在做目标检测时,图像中可能存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来;这样我们就需要这样的一个特征金字塔来完成这件事。
FPN 网络结构如下图所示:
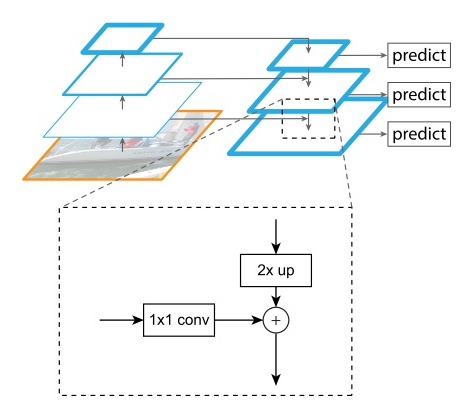
FPN 网络由两部分组成, bottom-up pathway 和 top-down pathway and lateral connections 。
2.1 bottom-up
bottom-up 是前馈网络的一部分,每一层向上使用 stride=2 对图像数据下采样,如上图左侧所示。
2.2 top-down and lateral connections
这一部分是自顶向下通过上采样(最近邻插值法)的方式将顶层的小特征图放大到上一个 stage 的特征图一样的大小。最近邻插值法,可以在上采样的过程中最大程度地保留特征图的语义信息(有利于分类),从而与 bottom-up 过程中相应的具有丰富的空间信息(高分辨率,有利于定位)的特征图进行融合,从而得到既有良好的空间信息又有较强烈的语义信息的特征图。然后在通过 lateral connections 网络将 bottom-up 和 top-down 的特征值进行拼接在一起,作为一个预测特征层,如上图右侧所示。
3. 代码实现
首先创建 ResNet 网络作为骨干网络,并声明用于作为预测特征层的层。
resnet_backbone = ResNet(Bottleneck, [3, 4, 6, 3], include_top=False)
return_layers = {'layer1': '0', 'layer2': '1', 'layer3': '2', 'layer4': '3'}
创建 BackboneWithFPN:
in_channels_list = [256, 512, 1024, 2048]
out_channels = 256
BackboneWithFPN(resnet_backbone, return_layers, in_channels_list, out_channels)
BackboneWithFPN 类中创建了两个类, IntermediateLayerGetter 和 FeaturePyramidNetwork 。
class BackboneWithFPN(nn.Module):
def __init__(self, backbone, return_layers, in_channels_list, out_channels):
super(BackboneWithFPN, self).__init__()
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
self.fpn = FeaturePyramidNetwork(
in_channels_list=in_channels_list,
out_channels=out_channels,
extra_blocks=LastLevelMaxPool(),
)
# super(BackboneWithFPN, self).__init__(OrderedDict(
# [("body", body), ("fpn", fpn)]))
self.out_channels = out_channels
def forward(self, x):
x = self.body(x)
x = self.fpn(x)
return x
IntermediateLayerGetter 类的作用是收集主干网络 (resnet-50) 的 layer4 层之前的各个岑层,之后的层舍弃。在前向传播 forward 过程中收集 layer1 、 layer2 、 layer3 、 layer4 的输出作为预测特征层。前向传播返回的是一个 OrderedDict ,健为初始化时传入的参数 return_layers 字典的值,值为主干网络前向传播后的特征层。
class IntermediateLayerGetter(nn.ModuleDict):
__annotations__ = {
"return_layers": Dict[str, str],
}
def __init__(self, model, return_layers):
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {k: v for k, v in return_layers.items()}
layers = OrderedDict()
# 遍历模型子模块按顺序存入有序字典
# 只保存layer4及其之前的结构,舍去之后不用的结构
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers:
break
super(IntermediateLayerGetter, self).__init__(layers)
self.return_layers = orig_return_layers
def forward(self, x):
out = OrderedDict()
# 依次遍历模型的所有子模块,并进行正向传播,
# 收集layer1, layer2, layer3, layer4的输出
for name, module in self.named_children():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out
接下来看 FeaturePyramidNetwork 类,首先看 init 函数:
init 函数中由两个重要的变量 inner_block_module 和 layer_block_module ,其中 inner_block_module 是 1x1 卷积层 ,元素相加时要保证特征有着相同的维度、高度和宽度,通过 1x1 卷积层调整维度。相加后后的特征通过 layer_blocks 3x3 的卷积层,用于减轻最近邻近插值带来的混叠影响,输出作为预测特征层。
extra_blocks 是最大池化层 max_pool2d 。
def __init__(self, in_channels_list, out_channels, extra_blocks=None):
super(FeaturePyramidNetwork, self).__init__()
self.inner_blocks = nn.ModuleList()
self.layer_blocks = nn.ModuleList()
for in_channels in in_channels_list:
if in_channels == 0:
continue
inner_block_module = nn.Conv2d(in_channels, out_channels, 1)
layer_block_module = nn.Conv2d(out_channels, out_channels, 3, padding=1)
self.inner_blocks.append(inner_block_module)
self.layer_blocks.append(layer_block_module)
# initialize parameters now to avoid modifying the initialization of top_blocks
for m in self.children():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_uniform_(m.weight, a=1)
nn.init.constant_(m.bias, 0)
self.extra_blocks = extra_blocks
下面看下两个接口 get_result_from_inner_blocks 和 get_result_from_layer_blocks :
get_result_from_inner_blocks 相当于 self.inner_blocks[idx] (x) ,执行 1x1 卷积调整维度。
get_result_from_layer_blocks 相当于 self.layer_blocks[idx] (x) ,执行 3x3 卷积进行特征融合。
def get_result_from_inner_blocks(self, x, idx):
# type: (Tensor, int)
"""
This is equivalent to self.inner_blocks[idx](x),
but torchscript doesn't support this yet
"""
num_blocks = 0
for m in self.inner_blocks:
num_blocks += 1
if idx < 0:
idx += num_blocks
i = 0
out = x
for module in self.inner_blocks:
if i == idx:
out = module(x)
i += 1
return out
def get_result_from_layer_blocks(self, x, idx):
# type: (Tensor, int)
"""
This is equivalent to self.layer_blocks[idx](x),
but torchscript doesn't support this yet
"""
num_blocks = 0
for m in self.layer_blocks:
num_blocks += 1
if idx < 0:
idx += num_blocks
i = 0
out = x
for module in self.layer_blocks:
if i == idx:
out = module(x)
i += 1
return out
forward 函数的输入为 IntermediateLayerGetter 实例的 forward 的输出,所以 x 为一个 OrderedDict 字典,健为 [0, 1, 2, 3] ,值为主干网络输出的预测特征层。
首先通过 1x1 的卷积层计算 layer4 的维度调整到指定大小,然后经过 3x3 卷积层得到对应的预测特征层。然后计算 layer3 到 layer1 的预测特征层,与 layer4 不同的是,这三层在调整维度大小后要与上一层进行上采样的特征进行对应元素相加,然后经过 3x3 卷积层得到对应的预测特征层。最后添加 extra_blocks 层,该层是最大池化层。中间的计算过程中将各个预测特征添加到 result 中,最后将 result 的值和 names 值存储到 OrderedDict 中输出。
def forward(self, x):
# type: (Dict[str, Tensor])
"""
Computes the FPN for a set of feature maps.
Arguments:
x (OrderedDict[Tensor]): feature maps for each feature level.
Returns:
results (OrderedDict[Tensor]): feature maps after FPN layers.
They are ordered from highest resolution first.
"""
# unpack OrderedDict into two lists for easier handling
names = list(x.keys())
x = list(x.values())
last_inner = self.inner_blocks[-1](x[-1])
results = []
results.append(self.layer_blocks[-1](last_inner))
for idx in range(len(x) - 2, -1, -1):
inner_lateral = self.get_result_from_inner_blocks(x[idx], idx)
feat_shape = inner_lateral.shape[-2:]
inner_top_down = F.interpolate(last_inner, size=feat_shape, mode="nearest")
last_inner = inner_lateral + inner_top_down
results.insert(0, self.get_result_from_layer_blocks(last_inner, idx))
# 在layer4对应的预测特征层基础上生成预测特征矩阵5
if self.extra_blocks is not None:
results, names = self.extra_blocks(results, names)
# make it back an OrderedDict
out = OrderedDict([(k, v) for k, v in zip(names, results)])
return out
至此,带有 FPN 网络的 resnet50 主干网路就介绍完了。