1. 概述
DenseNet 网络相比 ResNet 网络提出了更激进的稠密网络,即每一层都会与前面所有层在 channel 维度上进行拼接 (concat) 。而 ResNet 网络只在部分层进行维度上元素相加。
DenseNet 稠密网络结构如下图所示:
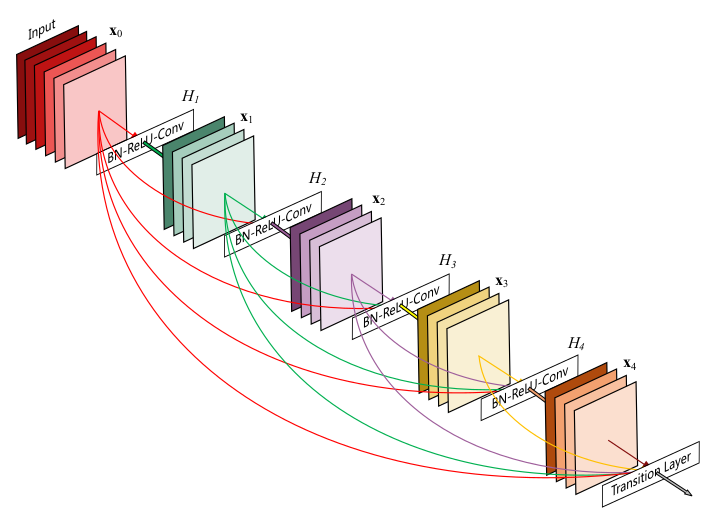
上图中函数 H 代表非线性转化函数 (non-liear transformation) ,它是一些列 BN 、 ReLU 、 Pooling 以及 Conv 操作的组合。 DenseNet 稠密连接模式,比如 H3 的输入不仅包括来自 H2 的输出 x2 ,还包括 H1 的输出 x1 和 输入 x0 ,它们是在 channel 维度上拼接 (concat) 在一起。
2. 网络结构
CNN 网络一般一般会通过 pooling 层或者通过步距大于 1 来压缩特征图的大小,而 DenseNet 网络的稠密连接需要特征图大小保持一致,为了解决此问题, DenseNet 网络中使用 DenseBlock+Transition 的结构,其中 DenseBlock 是包含多个层的模块,每个层的特征图大小相同,层与层之间采用稠密连接方式。而 Transition 模块是连接两个相邻的 DenseBlock ,并且通过 pooling 压缩特征图的大小。
DenseNet 网络结构如下图所示:

2.1 DenseBlock 结构
在 DenseBlock 中,各个层的特征图大小相同,可以在 channel 维度上拼接 (concat) 。 DenseBlock 中的非线性组合函数 H 采用的是 BN+ReLU+3x3 Conv 的结构。在 DenseNet 网络中,所有的 DenseBlock 中各个层的卷积核个数均为 k , k 在 DenseNet 论文中称为 growth rate ,这是一个超参数,由于 DenseNet 网络采用稠密连接的方式,使用较小的 k 值就可以得到很好的性能。假定输入层的特征图的 channel 数为 k0 ,那么 L 层输入的 channel 数为 k0 + k(L-1) ,因此随着层数增加,尽管 k 值较小, DenseBlock 的输入也会比较多,不过这是由于特征重用的原因,每个层仅有 k 个特征是自己独有的。
由于后面层的输入较大, DenseBlock 内部采用 Bottleneck 层来减少计算量 (这里与 ResNet 类似),主要是原有的结构中增加 1x1 Conv ,即 BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv ,称为 DenseNet-B 结构。其中 1x1 Conv 得到 4k 个特征图,起到压缩特征数量的作用,从而提升计算效率。
2.2 Transition 结构
Transition 网络,通过压缩特征图大小,使两个相邻的 DenseBlock 可以进行连接。 Transition 网络包括一个 1x1 的卷积和 2x2 的 AvgPooling ,结构为 BN+ReLU+1x1 Conv+2x2 AvgPooling 。此外, Transition 网络可以起到压缩模型的作用。如果 Transition 网络的上层 DenseBlock 得到的特征图 channels 数为 n , Transition 网络可以产生 [mn] 个特征(通过卷积层),其中 m=(0, 1] 是压缩系数 (compression rate) 。当 m=1 时,特征层个数经过 Transition 网络没有变化,即无压缩,而当压缩系数小于1时,这种结构称为 DenseNet-C ,论文中使用 m=0.5 。对于使用 Bottleneck 层的 DenseBlock 结构和压缩系数小于 1 的 Transition 网络组合结构称为 DenseNet-BC 。
2.3 网络结构
DenseNet 在各个层数下的网络结构如下图所示:
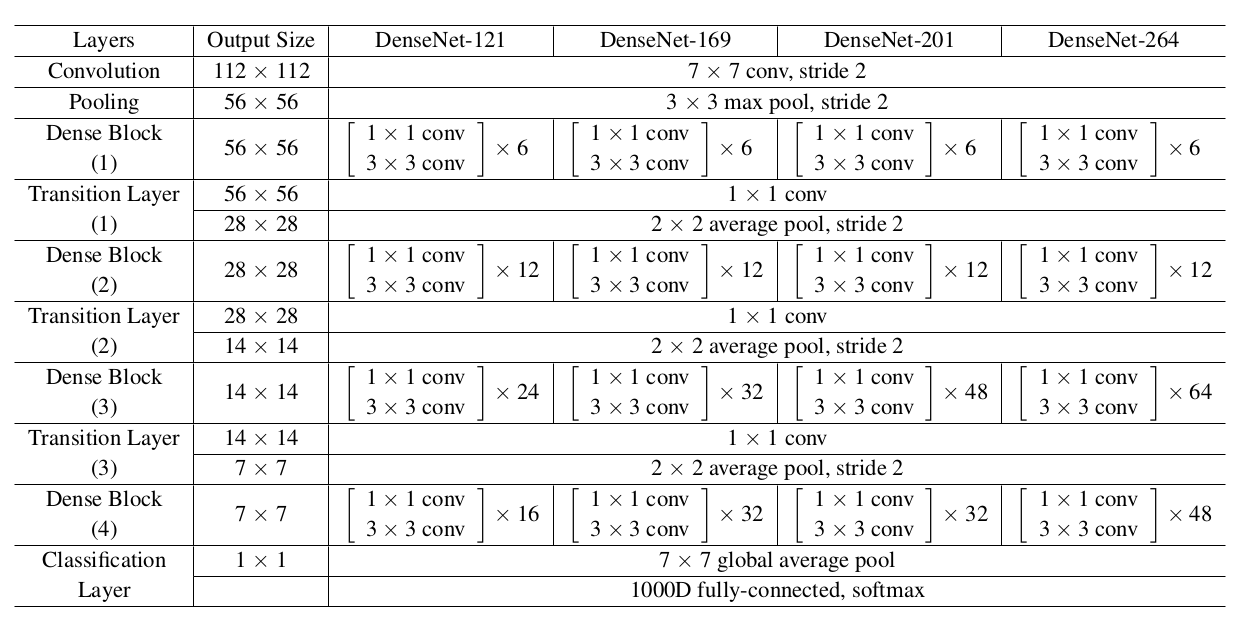
3. 代码实现
以 121 层网络为例:
def densenet121(pretrained=False, progress=True, **kwargs):
r"""Densenet-121 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
return _densenet('densenet121', 32, (6, 12, 24, 16), 64, pretrained, progress,
**kwargs)
_densenet 函数用于创建 Densenet 网络,参数如下:
- arch: 网络名称
- growth_rate: DenseBlock 中各个层的卷积核个数
- block_config: 每一个 DenseBlock 中网络层数
- num_init_features: 第一个 conv 层的卷积核个数
def _densenet(arch, growth_rate, block_config, num_init_features, pretrained, progress, **kwargs): model = DenseNet(growth_rate, block_config, num_init_features, **kwargs) if pretrained: _load_state_dict(model, model_urls[arch], progress) return modelDenseNet 网络实现:
参数
- bn_size: Bottleneck 中 1x1 conv 的 factor=4 , 1 x 1 conv 输出的通道数一般为 factor*K=128
- growth_rate: DenseBlock 中各个层的卷积核个数
- drop_rate: dopout rate
init 函数
创建 self.features
- conv0: 卷积核个数:64 卷积核大小: 7x7 ;步距: 2 ;填充: 3
- norm0: Batch Normalization
- relu0: ReLU
- pool0: 最大池化层,卷积核大小: 3x3 ;步距: 2 ;填充: 1
- 根据 block_config 创建 _DenseBlock , block_config 是一个链表,链表的长度代表有多少个 DenseBlock 结构,每个元素的大小代表 DenseLayer 的个数
- 每个 DenseBlock 结构之间通过 Transition 连接
- 添加 Batch Normalization 层 norm5
创建 self.classifier
- 由一个全连接层组成
初始化参数
forward 函数
- 在 self.features 后增加 relu 、 自适应平均池化层 、展平处理
class DenseNet(nn.Module): def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000, memory_efficient=False): super(DenseNet, self).__init__() # First convolution self.features = nn.Sequential(OrderedDict([ ('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)), ('norm0', nn.BatchNorm2d(num_init_features)), ('relu0', nn.ReLU(inplace=True)), ('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)), ])) # Each denseblock num_features = num_init_features for i, num_layers in enumerate(block_config): block = _DenseBlock( num_layers=num_layers, num_input_features=num_features, bn_size=bn_size, growth_rate=growth_rate, drop_rate=drop_rate, memory_efficient=memory_efficient ) self.features.add_module('denseblock%d' % (i + 1), block) num_features = num_features + num_layers * growth_rate if i != len(block_config) - 1: trans = _Transition(num_input_features=num_features, num_output_features=num_features // 2) self.features.add_module('transition%d' % (i + 1), trans) num_features = num_features // 2 # Final batch norm self.features.add_module('norm5', nn.BatchNorm2d(num_features)) # Linear layer self.classifier = nn.Linear(num_features, num_classes) # Official init from torch repo. for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight) elif isinstance(m, nn.BatchNorm2d): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): nn.init.constant_(m.bias, 0) def forward(self, x): features = self.features(x) out = F.relu(features, inplace=True) out = F.adaptive_avg_pool2d(out, (1, 1)) out = torch.flatten(out, 1) out = self.classifier(out) return out
创建 _DenseBlock
init 函数
- 根据 num_layers 创建 _DenseLayer
forward 函数
- 计算 new_features , 并在维度 1 上与 features 进行拼接
class _DenseBlock(nn.ModuleDict): _version = 2 def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate, memory_efficient=False): super(_DenseBlock, self).__init__() for i in range(num_layers): layer = _DenseLayer( num_input_features + i * growth_rate, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate, memory_efficient=memory_efficient, ) self.add_module('denselayer%d' % (i + 1), layer) def forward(self, init_features): features = [init_features] for name, layer in self.items(): new_features = layer(features) features.append(new_features) return torch.cat(features, 1)
创建 _DenseLayer
init 函数
- Bottleneck 结构: BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv
class _DenseLayer(nn.Module): def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, memory_efficient=False): super(_DenseLayer, self).__init__() self.add_module('norm1', nn.BatchNorm2d(num_input_features)), self.add_module('relu1', nn.ReLU(inplace=True)), self.add_module('conv1', nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)), self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)), self.add_module('relu2', nn.ReLU(inplace=True)), self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)), self.drop_rate = float(drop_rate) self.memory_efficient = memory_efficient def bn_function(self, inputs): # type: (List[Tensor]) -> Tensor concated_features = torch.cat(inputs, 1) bottleneck_output = self.conv1(self.relu1(self.norm1(concated_features))) # noqa: T484 return bottleneck_output # todo: rewrite when torchscript supports any def any_requires_grad(self, input): # type: (List[Tensor]) -> bool for tensor in input: if tensor.requires_grad: return True return False @torch.jit.unused # noqa: T484 def call_checkpoint_bottleneck(self, input): # type: (List[Tensor]) -> Tensor def closure(*inputs): return self.bn_function(inputs) return cp.checkpoint(closure, *input) @torch.jit._overload_method # noqa: F811 def forward(self, input): # type: (List[Tensor]) -> (Tensor) pass @torch.jit._overload_method # noqa: F811 def forward(self, input): # type: (Tensor) -> (Tensor) pass # torchscript does not yet support *args, so we overload method # allowing it to take either a List[Tensor] or single Tensor def forward(self, input): # noqa: F811 if isinstance(input, Tensor): prev_features = [input] else: prev_features = input if self.memory_efficient and self.any_requires_grad(prev_features): if torch.jit.is_scripting(): raise Exception("Memory Efficient not supported in JIT") bottleneck_output = self.call_checkpoint_bottleneck(prev_features) else: bottleneck_output = self.bn_function(prev_features) new_features = self.conv2(self.relu2(self.norm2(bottleneck_output))) if self.drop_rate > 0: new_features = F.dropout(new_features, p=self.drop_rate, training=self.training) return new_features